In SQL server 2022, we finally have an ORDER option when we create a columnstore index. But what does it really do?
Some basics first:
If you are familiar with rowgroups, segments and segment elimination, then you can skip this section.
Data for a columnstore index is divded in groups of approximate 1 million rows, rowgroups. Each rowgroup has a set of pages for each column. The set of pages for a column in a rowgroup is called a segment. SQL Server has meta-data for the lowest and highest value for a segment. There are no SEEKs in a columnstore index. But, SQL Server can use this meta-data to skip reading segments, with the knowledge that “this segment cannot contain any data that I need based on my predicates in my WHERE clause”.
Also, you might want to do these operations using MAXDOP 1, so we don’t have several threads muddling our neat segment alignment.
Making sure the data is sorted when building the index
Say that you want the rows with the earliest OrderDates in the first rowgroup, then the next 1 million rows (based on OrderDate) in the next rowgroup… and finally the most recent rows in the last rowgroup. We can do that without ORDER by “happening” to have a row-index on the same set of columns sorted in the way that we want the columnstore index to be sorted when building the index. I.e., SQL Server takes the path of least resistance and uses that row index when building the columnstore index. You achieve this by having a rowstore index with matching column key and re-create it as a columnstore index using DROP_EXISTING.
The new ORDER specification in SQL Server 2022 for the clustered columnstore index takes care of this for you. Nice.
Making sure the data is sorted when adding more data
The ORDER you specified for the clustered columnstore index is reflected in sys.index_columns, the column_store_order_ordinal column. This is used by the engine when you load data. Data will be sorted and loaded in that order.
This is fine if you add data aligned as how you have the ORDER specified. Say you have it on OrderDate and as you add new orders, you get new rowgroups for the new orders based on new data coming in will have increasing OrderDate.
This is a common situation, but what if the ORDER for the index doesn’t match with how the new data arrives? Then over time, you have added rowgroups containing data all over the place, including the segment(s) for the column(s) that you specified for the ORDER clause.
Making sure the data is sorted when rebuilding the index
This is what surprised me. I was expecting the column_store_order_ordinal column in sys.index_columns to be respected when I do ALTER INDEX REBUILD. But it isn’t. Nor is it respected if I do CREATE INDEX … WITH DROP_EXISTING.
So, bottom line is that we still have to use DROP_EXISTING to convert the table to a rowstore table, having a clustered index key that will match our ORDER. And then convert it again, to a columnstore table using that ORDER definition. Just like we are doing today.
Above is what my tests indicates. Let me know if I missed something obvious.
Here is the T-SQL I ran, requires the AdventureworksDW database.
USE AdventureworksDW
GO
--Supporting proc
CREATE OR ALTER PROC GetSegmentAlignment
@tablename sysname
AS
SELECT
COL_NAME(ic.object_id, ic.column_id) as ColumnName
,s.segment_id
,s.min_data_id
,s.max_data_id
,s.row_count
,s.on_disk_size
FROM sys.column_store_segments AS s
INNER JOIN sys.partitions AS p ON p.hobt_id = s.hobt_id
INNER JOIN sys.indexes AS i ON i.object_id = p.object_id AND i.index_id = p.index_id
LEFT JOIN sys.index_columns AS ic ON ic.object_id = i.object_id AND ic.index_id = i.index_id AND ic.index_column_id = s.column_id
WHERE OBJECT_NAME(p.object_id) = @tablename
AND ic.column_id IS NOT NULL
ORDER BY s.column_id, p.partition_number, s.segment_id
GO
DROP TABLE IF EXISTS NewFact
GO
--Create heap using SELECT INTO
SELECT * INTO NewFact
FROM FactResellerSalesXL_CCI
WHERE UnitPrice < 400
--Create the ORDERed clustered columnstore index
CREATE CLUSTERED COLUMNSTORE INDEX NewFact ON NewFact ORDER(OrderDateKey) WITH(MAXDOP = 1)
--Verify index is ORDERed
SELECT i.name, i.type_desc, c.column_id, COL_NAME(c.object_id, c.column_id) as ColumnName, c.column_store_order_ordinal
FROM sys.indexes AS i
INNER JOIN sys.index_columns AS c ON i.index_id = c.index_id AND i.object_id = c.object_id
WHERE i.object_id = OBJECT_ID('NewFact')
--Check segment alignment, nicely aligned on OrderDateKey
EXEC GetSegmentAlignment 'NewFact'
--Load the rest of the data
INSERT INTO NewFact
SELECT *
FROM FactResellerSalesXL
WHERE UnitPrice >= 400
EXEC GetSegmentAlignment 'NewFact'
--The whole table is not re-aligned, but *new* data is aligned based on indexe's ORDER
--Try any of below
ALTER INDEX NewFact ON NewFact REBUILD WITH (MAXDOP = 1)
EXEC GetSegmentAlignment 'NewFact'
--Segments are not aligned
CREATE CLUSTERED COLUMNSTORE INDEX NewFact ON NewFact ORDER(OrderDateKey) WITH(DROP_EXISTING = ON, MAXDOP = 1)
EXEC GetSegmentAlignment 'NewFact'
--Segments are not aligned
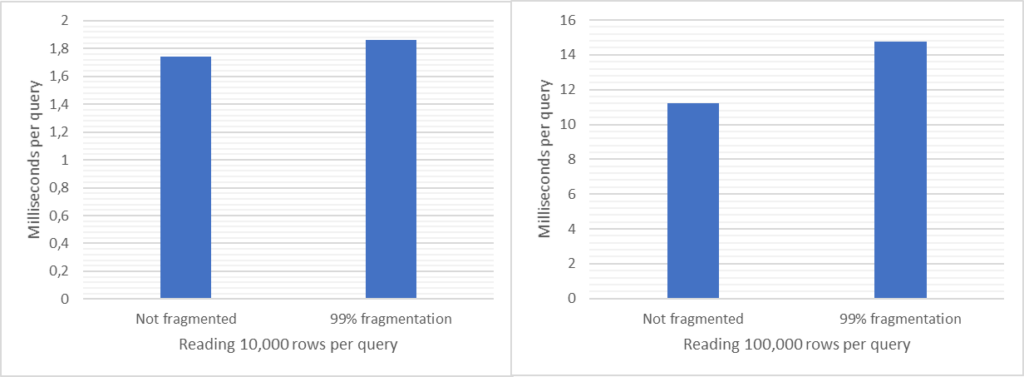
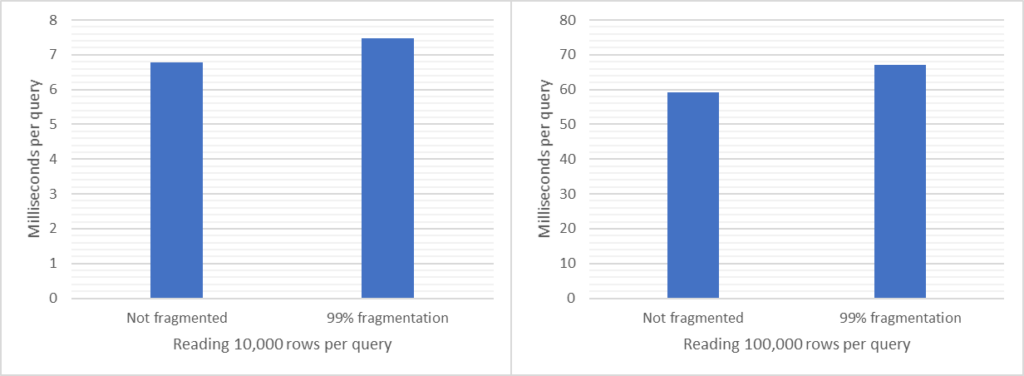
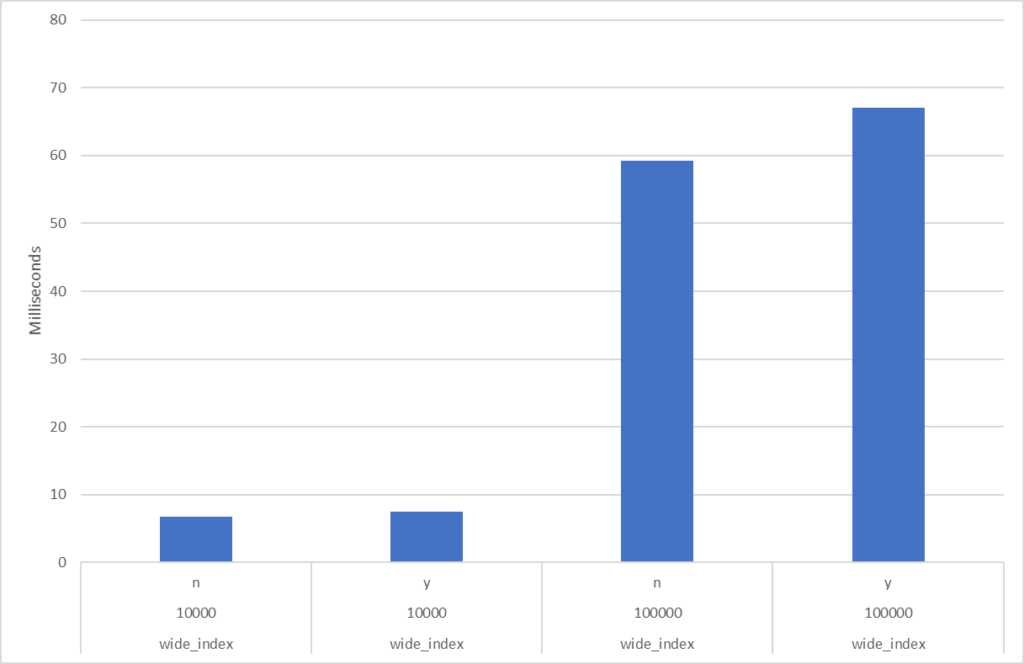
How much do you gain from defragmenting your indexes?
Let me show you. Below are diagrams for tables (indexes) with 0% fragmentation vs. over 99% fragmentation. To the left is response time for the an unfragmented index and to the right is fragmented index. The query is super-simple doing pretty much only I/O (physical, not cached) and doesn’t return any data to the client. I.e., we pretty much compare only the I/O portion:
Narrow indexWide index
Not that much, huh? Read on for details:
Background
It has been a few years since I wrote about index fragmentation. For my earlier posts, I both elaborate in writing about the topic and I also ran some tests to try to quantify the difference. I want to revisit the topic for a few reasons:
I want to have one (1) post to point to when this topic comes up.
I want to clean up the text.
I’m running these tests on my laptop, and I have a new laptop since I last ran the tests. (I’d love to run these on a real server, but there are many reasons why that isn’t doable/practical for me.)
The last time i wrote three blog posts. The main reason for that was that my tests for the first and second blog posts were flawed (because of buffer pool ramp-up and auto-stats).
In the end I want to discuss internal and external fragmentation and also show some numbers. The numbers are of course what I measured on my machine with my load. You find the T-SQL code at the end if you want to play with this yourself. Some of the text below are from my earlier blog posts.
TLDR
See numbers and diagrams at the end, or at the top. I measured a few cases: the difference between no external fragmentation and severe external fragmentation (over 99%). I have both a narrow index and a wide index, and I read one (1), 10,000 and 100,000 rows using index searches (“range scan”). There were obviously no difference reading 1 row so I exclude that from my discussion below. For the other cases the extra time with an extreme level of external fragmentation is (from lowest impact to highest) 7%, 10%, 13% and 32%. The highest number (32%) is when reading many rows from a narrow index, i.e. many rows per page. Again, this is with an extreme level of fragmentation.
What is index fragmentation?
By index here I mean b-tree indexes. You know, the regular types of indexes. I’m not referring to “odd” indexes such as columnstore, hash, geospatial, fulltext, or xml indexes. For a b-tree index (from now on, I will just say “index”), the leaf level is stored according the order of the index key. I.e., the leaf is sorted. As you modify data, you can get page splits. Imagine inserting a row “in the middle” and there’s no room on the page. SQL server will split the page, by inserting a page from somewhere into the linked list, move 50% to that new page, and then add the row to where it should be.
If you now follow the linked list, you jump back and forth in the data file: external fragmentation.
The page split left us with two (nearly) half-full pages: internal fragmentation.
What do we do about it?
Duh, we defragment the indexes, of course! The two commonly used methods are:
Rebuild the indexes. ALTER INDEX … REBUILD. This will create a new index and then remove the old index. This requires free space in the database file(s) about the same size as the index.
Reorganize the index. ALTER INDEX … REORGANIZE. Basically walk the linked list and for every time you have to go backward in the file when going to the next page, you swap these two pages. It does a bit more than that (re-introduce the fillfactor), but essentially swapping places of the pages not going forwards physically in the file.
While doing defrag, we might leave some free space on each page (aka fillfactor). Rebuild allow us to specify the fillfactor, while reorg will re-apply whatever value you specified when creating the index.
Why might fragmentation hurt us?
Several aspects here. Let us discuss them one by one:
Lots of empty space
Yes, a page split leaves us with two half-full pages. At that point in time. But as more rows are added, they will fit on that free space.
In the end, you will probably average at about 75% fullness (75% being in between half-full and full). That is for indexes where the inserts (and possibly updates) are inserted “all over the place”.
But we also have increasing indexes. Think columns such as “OrderDate”. Or identity/sequence columns, which are pretty often primary keys, which in turn pretty often are also the clustered index. For such an index, inserts will always add rows to the end of the linked list, and SQL Server will just add pages to the end – not “splitting” any page. (Yeah, adding a page to the end of the linked list is technically called a page split in SQL Server lingo, but that show more the problems that SQL server has with terminology than anything else.) The point here is that increasing indexes will not have free space in them because of inserts going to the end.
Common values I’ve seen for fillfactor in rebuild scripts are between 70 and 80%.
For increasing indexes, that just make the indexes bigger. And remember that it isn’t unlikely that the actual data is an increasing index (the clustered index). So, instead of having a 100 GB table, you now have a 120 GB table.
For other indexes, you probably get about the same size “naturally” (without doing defrag) as when doing a defrag (depending on your fillfactor, of course).
Pages are out of order
Ask your SAN people how much difference there is between sequential I/O and random I/O in your SAN. The answer to this question will tell you whether this point is relevant. For a single spinning disk, there is a big difference. With sequential I/O you don’t have the disk head movement. But as you introduce more disks in various RAID configs, add in a SAN in the mix and now have a bunch of disks and also other concurrent activity apart from your SQL Server in that SAN, the picture isn’t so clear anymore. Now add SSD or some similar technology to the mix. In the end, there might not be much of a difference between random and sequential I/O on a modern storage solution.
Splitting a page takes time
Yup, sure does. If you can defragment frequently enough with a chosen fillfactor for each index so that they never split, then you avoid this. But how many of us do that? I.e., hand craft the chosen fillfactor for each index by observing the amount of fragmentation for each index since last time we did defrag, and repeat this week after week until we tuned the “perfect” fillfactor for each index? Some of us might actually do that, but as a consultant, I can tell you that none of my clients have opted for me to do that type of work. In the end, I’m not that certain that we reduce page splits by doing our regular defrag, at least not to the extent that we hope for.
Splitting writes to the transaction log.
Yes, it does. But again, how much difference is there in reality between defrag and not defrag regarding page splits occurring during business hours.
Why might doing defrag hurt us?
Of course there is another side of the coin! Defrag isn’t free. When people asking me whether to defrag, a short question back from me is “How much does it hurt?” If the answer is “None at all”, then sure go ahead! If the answer is “A lot!”, then we want to think twice.
It reduces concurrency because of locking
Rebuild has an ONLINE option available if you are on Enterprise Edition (EE), which makes the rebuild essentially online. But using online causes the rebuilt to take longer time compared to offline.
If not on EE, then the whole table will be locked.
Shared lock if the rebuild is on a nonclustered index – this allow concurrent reads but not modifications.
Exclusive locks if the index is a clustered index – disallowing both read and modifications.
Reorg will only put a brief lock of the two pages “where it currently is”. This makes reorg much more online-ish than rebuild on non-EE.
It puts load your system
Say you have a 200 GB database, and rebuild everything. Now you shuffle 200 GB data. This isn’t free. Even if you use smarter scripts to only defrag what is actually fragmented in the first place, defrag will probably shuffle quite a lot of data. Your VM/SAN/SQL/whatever probably have other things to do at night-time. We all fight over these precious night/weekend hours. And for systems that are expected to be online pretty much all the time, this is even more pressing. Now throw this into the cloud and you can convert that type of work into real money!
You will need a larger LDF file
If you rebuild everything (blindly) then the ldf file need to be the same size as the (sum of) data file(s). A smart script perhaps only rebuild 30% of the data, cutting this down to some 30% of the data size. (This doesn’t apply to simple recovery model.)
The following log backup will be large
Again, if you rebuild 100 GB worth of indexes, then the subsequent log backup will be 100 GB in size. Etc. You get the picture by now. (Again this doesn’t apply to simple recovery model.)
What about page fullness?
To be honest, I find this to be a much more interesting aspect. I’d like to split this into two sub-sections. Increasing and “random” index.
Increasing index
This can be like an identity or ever increasing datetime column (think for instance order_date). This will not become fragmented from INSERTS and assuming that you don’t delete “every other row”, then you will end up with a nice unfragmented index with a high degree of page fullness. If you rebuild it with a fillfactor of 100%, you have just wasted resources. If you rebuild it with a lower fillfactor, you also waste space and cause SQL Server to read more data when the index is used – causing worse performance.
Random index
By this I mean index where the data distribution is all over the place. For instance an index on the LastName column. As you insert data, pages are split and you end up with a fillfactor of about 75% (which is in between a half-full and a full page). If you rebuild it with a similar fillfactor, you didn’t gain anything. If you rebuild it with a high fillfactor, then the following activity in your database will generate a high number of page splits. It seems reasonable to let it be, accepting a fillfactor of about 75% and accept a page split happening every now and then.
But we also delete data!
Do you? Really? OK, let us say that you do. What is the delete pattern? And the degree of deletes? How does this spread over your particular index? Deleting old data over some ever increasing index will just deallocate those pages. Deleting data which doesn’t match with the index key (rows deleted are spread all over the index) will leave empty space. This will be re-used as you insert new rows. But if you delete a lot of data all over the place, then you will have a low degree of page fullness. IMO, this is a rather unusual situation and should warrant a manually triggered index maintenance, in contrast to rebuilding indexes every week or so. (And don’t get me started on heaps, but surely you don’t have those…? I once had a SELECT of all rows for a table with only 3000 rows, which took minutes. It had allocated more extents than number of rows in the table. Rebuild the heap, and that SELECT took, of course, sub-second. Until this degraded again, over time. Needless to say, this didn’t stay as a heap for long. And no, the table wasn’t wide, at all.)
But my friend had a query that went from 10 minutes to 1 second after defrag!
Yeah, that was because the statistics were also updated by the index rebuild resulting in a different execution plan. As soon as you see big differences, it is because of statistics update, not the defrag per se.
I like to provide the optimizer with as high-quality statistics as possible. Sure, index rebuild will give you new statistics. But if you condition it based on fragmentation, then you end up with not rebuilding a bunch of indexes and have stale statistics. Auto update statistics is OK, but you have to modify a decent amount of data before it kicks in. And when it kicks in, the user waits for it. Unless you do async update…. But I digress. Statistics management is a topic of its own. My point is that you probably don’t want to lose track of statistics management because you keep staring as index fragmentation.
Things to consider and watch out for
Here are some of the things that can throw you off when you play with these things.
Auto-update of statistics
I was bitten by this on my first test. I did a SELECT after modifying many rows (which fragmented the index) and this triggered auto-update statistics, meaning that SELECT took a very long time.
Buffer pool ramp-up
If you have Enterprise Edition, then there’s a “smartness” that reads more data than necessary if you have lots of free memory. Paul White told me about a lesser known optimization where SQL server will do “large I/O” (my own term for this) if you have plenty of unused memory. Instead of reading single pages, it reads whole extents. This makes sense, warming up the cache. https://blogs.msdn.microsoft.com/ialonso/2011/12/09/the-read-ahead-that-doesnt-count-as-read-ahead/
Read-ahead
Just for fun, I ran my tests while disabling read-ahead (aka sequential-prefetch) and it took from 3 to 8 times longer with RA disabled. So, yes, RA can make a huge difference.
Show me the numbers already!
OK, sure! Some basics first: I was using two tables, both with a clustered index. I’m focusing on external fragmentation, i.e., jumping back and forth on disk when following the linked list. For both cases I was using a clustered index. The query seeked the index, and then followed the linked list to read as many pages/rows from the leaf that satisfied the search condition. I was both using a narrow index (about 200 rows per page) and a wide index (about 11 rows per page). I ran the queries a with 10,000 and also 100,000 rows selectivity. I didn’t re-read the same rows, so for each SELECT, the rows were read from disk.
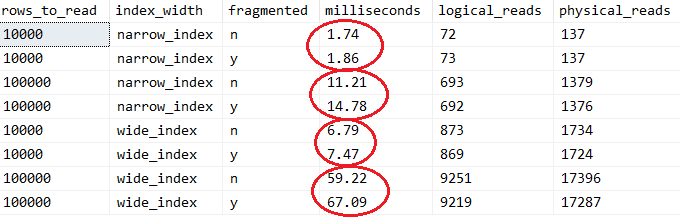
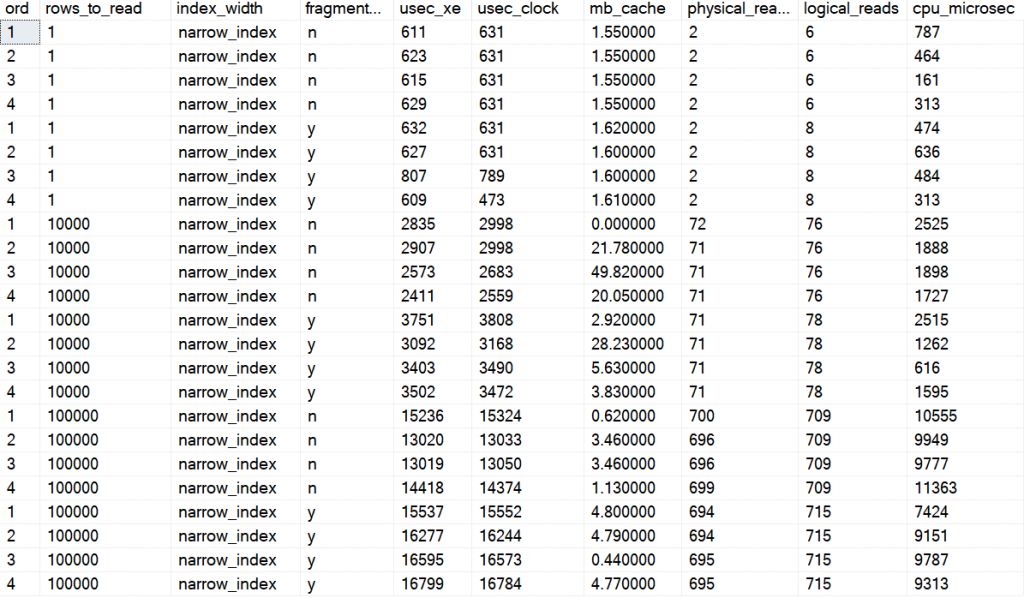
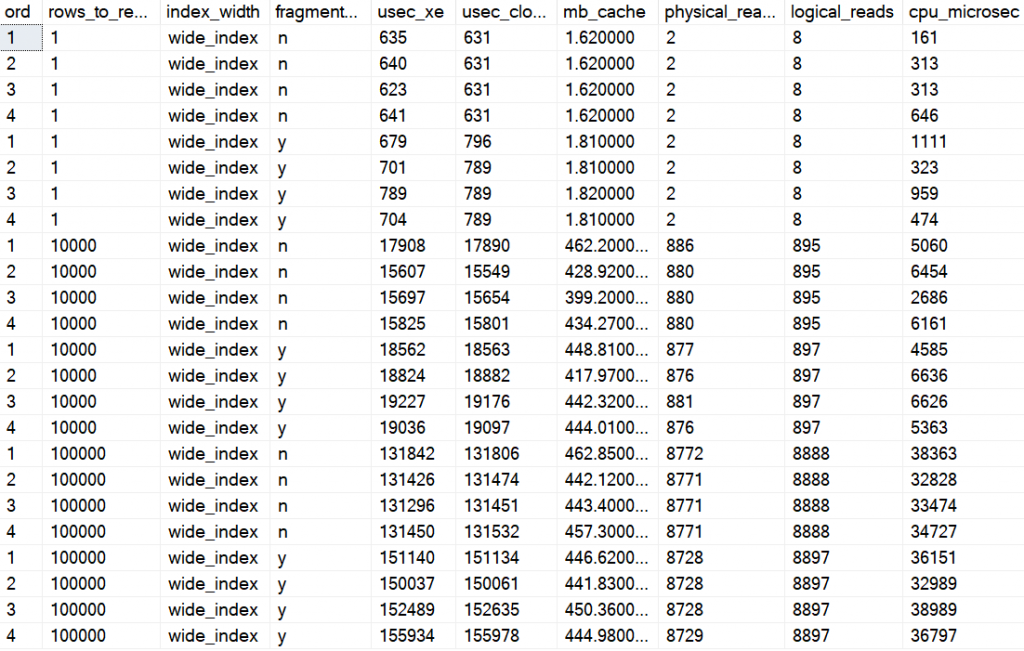
Compare the numbers in the red circles. This is the average elapse time per SELECT. The top within each circle is without fragmentation and bottom is with over 99% fragmentation.
Some facts:
I executes a SELECT statement several times, not reading the same data over and over again.
For the millisecond column I measured the time it took to execute all queries and divide with number of queries. I.e., it is an average per query.
For the logical_reads and physical_reads columns I used and Extended Events trace to capture number of I/O per SELECT statement and then average those numbers.
I did a rebuild with a fillfactor to achieve the same page fullness. See above section about page fullness for a discussion of that topic. For this test I was interested in external fragmentation.
Note a higher number of physical reads than logical reads. That is read-ahead in action. When disabling RA, I had the same numbers for both physical and logical reads (and between 3 to 8 times longer elapse time).
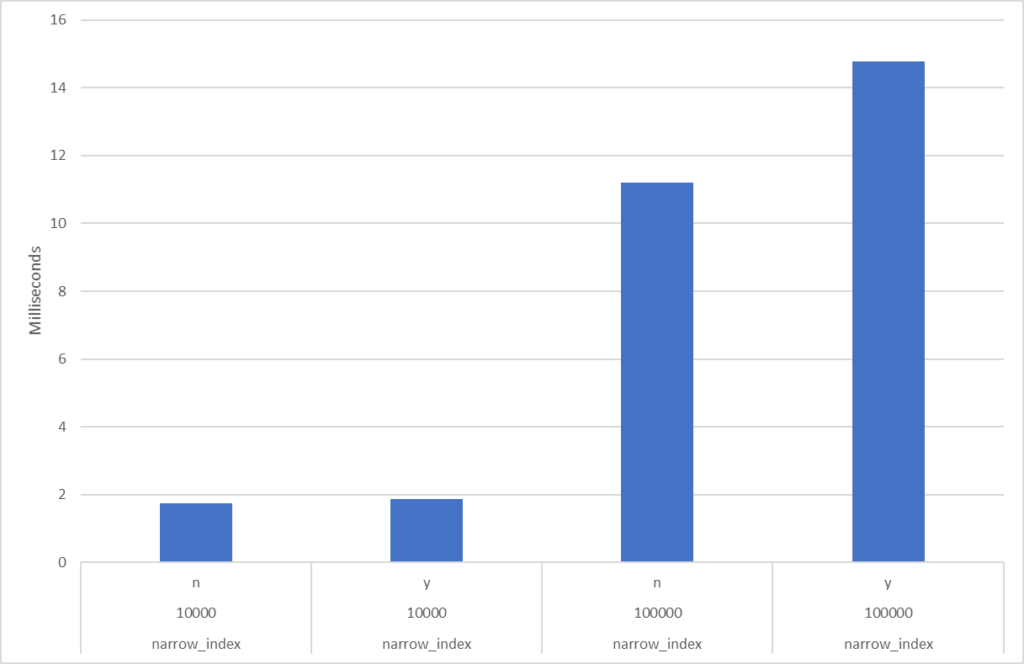
Here are some diagrams over the numbers. The narrow index, with no fragmentation (n) and high fragmentation (y), and reading 10,000 and 100,000 rows:
And the wide index, again with no fragmentation (n) and high fragmentation (y), and reading 10,000 and 100,000 rows:
What about the old blog posts?
I have added pretty much everything into this blog post, but in case you want to check them out:
This section is about the code I used. Feel free to use it for your own tests. Below is the basic flow of the code, from my last blog post. I did some modifications and tidy-up of the code for this new blog post, but I’m too lazy to go over the bulleted list below to reflect those changes.
Create a proc which does bunch of reads to fill the buffer pool with data.
Create some other supporting stuff, like trace definition, trace control procedure etc.
Grow the data and log files for the Stackoverflow (10 GB) database.
Create table to hold my measures.
Create the narrow_index table which is a table with a clustered index which is narrow. A row is some 40 bytes (very rough calculation off the top of my head).
Create the wide_index is a table with a clustered index which is wider – some 340 bytes.
Set max server memory to 1 GB.
Turn off auto-update statistics.
Create the proc that will do the tests.
Generate fragmentation in both indexes/tables.
The narrow table has 20,000,000 rows and is about 970 MB in size.
The wide table has 10,000,000 rows and is about 6.8 GB in size.
Run the proc that does the test with 1 row selectivity.
Run the proc that does the test with 10000 rows selectivity.
Run the proc that does the test with 100000 rows selectivity.
Each test runs 99 SELECTs, spread over the data (so not to read the same row).
Average the result, into a table named resx.
I did 4 such iterations, so I have the tables res1, res2, res3 and res4.
Check the numbers from these tables and see if they correspond reasonably. They did.
Average the results from these four table to get the end results.
The procedure which executes the SELECTS and captures the measures has this basic flow
Stop the (XE) trace if it is running.
Delete all old trace files.
Do a first SELECT to get rid of auto-stats (yeah, I disabled it, but just in case).
Empty the cache.
Reads lots of other data into cache.
Start the trace
Do the SELECT, in a loop, reading as many rows as requested (param to the proc), as many times as requested (another param to the proc). Don’t read the same data over and over again. This is done both for the narrow and wide table/index.
Capture memory usage for each table (buffer pool usage).
Get the trace raw data into a temp table.
Parse the trace data/above table using XQuery into the measures table.
Ie., we now have one row for each SELECT with a bunch of measures.
T-SQL
--Measure cost of fragmentation in terms of execution time and memory usage
--Tibor Karaszi, 2019. Revisited and modified 2022.
--Requires the Stackoverflow database. I was using the 10 GB version.
SET NOCOUNT ON
--Setup section
USE StackOverflow
GO
--Proc to study plans
CREATE OR ALTER VIEW vShowPlans
AS
SELECT
DB_NAME(sql.dbid) AS db_name_
,OBJECT_NAME(sql.objectid) AS object_name_
,p.cacheobjtype
,p.objtype
,s.execution_count
,s.total_worker_time --Add whatever measures you want
,p.size_in_bytes / 1024 AS size_in_kB
,SUBSTRING (sql.[text],(s.statement_start_offset/2) + 1,((CASE s.statement_end_offset WHEN -1 THEN DATALENGTH(sql.[text]) WHEN 0 THEN DATALENGTH(sql.[text]) ELSE s.statement_end_offset END - s.statement_start_offset)/2) + 1) AS text_query
,sql.text AS text_batch
,qp.query_plan
--,*
FROM sys.dm_exec_query_stats AS s
INNER JOIN sys.dm_exec_cached_plans AS p ON s.plan_handle = p.plan_handle
CROSS APPLY sys.dm_exec_sql_text(s.plan_handle) AS sql
CROSS APPLY sys.dm_exec_query_plan(s.plan_handle) AS qp
WHERE sql.dbid <> 32767 --Igorera resursdatabasen
GO
--Proc to fill buffer pool, reads lots of data, takes a while to execute
CREATE OR ALTER PROC fill_bp
AS
DECLARE @a bigint
SET @a = (SELECT AVG(CAST(PostId AS bigint)) FROM Comments)
SET @a = (SELECT AVG(CAST(CommentCount AS bigint)) FROM Posts)
SET @a = (SELECT AVG(CAST(PostId AS bigint)) FROM Comments)
SET @a = (SELECT AVG(CAST(VoteTypeId AS bigint)) FROM Votes)
SET @a = (SELECT AVG(CAST(PostId AS bigint)) FROM Comments)
SET @a = (SELECT AVG(CAST(VoteTypeId AS bigint)) FROM Votes)
SET @a = (SELECT AVG(CAST(VoteTypeId AS bigint)) FROM Votes)
GO
--Disable IAM order scan, so we know that SQL Server will follow the linked list
--See https://sqlperformance.com/2015/01/t-sql-queries/allocation-order-scans
EXEC sp_configure 'cursor threshold', 1000000 RECONFIGURE
GO
--Run the initial "prepp" section without restrictions, so it doesn't take too long
EXEC sp_configure 'max server memory', 26357 RECONFIGURE
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0
GO
--Proc to change trace status
CREATE OR ALTER PROC change_trace_status
@state varchar(50) --start, stop, delete_all_files
AS
IF @state = 'start' BEGIN IF NOT EXISTS (SELECT * FROM sys.dm_xe_sessions WHERE name = 'frag_test') ALTER EVENT SESSION frag_test ON SERVER STATE = START END IF @state = 'stop' BEGIN IF EXISTS (SELECT * FROM sys.dm_xe_sessions WHERE name = 'frag_test') ALTER EVENT SESSION frag_test ON SERVER STATE = STOP END --Delete XE file, using xp_cmdshell (ugly, I know) IF @state = 'delete_all_files' BEGIN EXEC sp_configure 'xp_cmdshell', 1 RECONFIGURE WITH OVERRIDE EXEC xp_cmdshell 'DEL C:\R\frag_test*.xel', no_output EXEC sp_configure 'xp_cmdshell', 0 RECONFIGURE WITH OVERRIDE END /* EXEC change_trace_status @state = 'start' EXEC change_trace_status @state = 'stop' EXEC change_trace_status @state = 'delete_all_files' */
GO
--Drop and create event session to keep track of execution time
EXEC change_trace_status @state = 'stop'
WAITFOR DELAY '00:00:01'
IF EXISTS (SELECT * FROM sys.server_event_sessions WHERE name = 'frag_test')
DROP EVENT SESSION frag_test ON SERVER
EXEC change_trace_status @state = 'delete_all_files'
CREATE EVENT SESSION frag_test ON SERVER
ADD EVENT sqlserver.sp_statement_completed()
ADD TARGET package0.event_file(SET filename=N'C:\R\frag_test')
WITH (MAX_DISPATCH_LATENCY=10 SECONDS)
GO
--Create proc to report progress
CREATE OR ALTER PROC #status
@msg varchar(200)
AS
RAISERROR(@msg, 10, 1) WITH NOWAIT
GO
--Grow the data and log files for StackOverflow database.
EXEC #status 'Grow the data and log files for StackOverflow database…'
IF EXISTS( SELECT size * 8/(1024*1024), *
FROM sys.database_files
WHERE name = N'StackOverflow2010' AND size * 8/(1024*1024) < 30)
ALTER DATABASE [StackOverflow] MODIFY FILE ( NAME = N'StackOverflow2010', SIZE = 30GB )
IF EXISTS( SELECT size * 8/(1024*1024), *
FROM sys.database_files
WHERE name = N'StackOverflow2010_log' AND size * 8/(1024*1024) < 15)
ALTER DATABASE [StackOverflow] MODIFY FILE ( NAME = N'StackOverflow2010_log', SIZE = 15GB )
GO
--Table to hold output
DROP TABLE IF EXISTS measures
CREATE TABLE measures (
id int identity(1,1) PRIMARY KEY NOT NULL
,rows_to_read int NOT NULL
,index_width varchar(20) NOT NULL
,fragmented varchar(2) NOT NULL
,usec_xe bigint NOT NULL
,usec_clock bigint NOT NULL
,cpu_microsec bigint NOT NULL
,physical_reads bigint NOT NULL
,logical_reads bigint NOT NULL
,mb_cache decimal(9,2) NOT NULL
);
--Create the table for the narrow index
EXEC #status 'Setup section. Create table with narrow index…'
DROP TABLE IF EXISTS narrow_index
--Adjust numbers. 20,000,000 rows means about 970 MB in the end
--540 MB with dense data (we do not measure on this)
--970 MB after fragmentation/rebuild with a fillfactor to get same number of pages as wehn data is fragmented
SELECT TOP(1000100020) ROW_NUMBER() OVER( ORDER BY (SELECT NULL)) AS c1, CAST('Hello' AS varchar(82)) AS c2
INTO narrow_index
FROM sys.columns AS a, sys.columns AS b, sys.columns AS c
CREATE CLUSTERED INDEX x ON narrow_index(c1)
--Create the table for the wide index
EXEC #status 'Setup section. Create table with wide index…'
DROP TABLE IF EXISTS wide_index
--Adjust numbers. 10,000,000 rows give us about
--3.4 GB with dense data (we do not measure on this)
--6.8 GB after fragmentation/rebuild with a fillfactor to get same number of pages as wehn data is fragmented
SELECT
TOP(1000100010) ROW_NUMBER() OVER( ORDER BY (SELECT NULL)) AS c1
,CAST('Hi' AS char(80)) AS c2
,CAST('there' AS char(80)) AS c3
,CAST('I''m' AS char(80)) AS c4
,CAST('on' AS char(80)) AS c5
,CAST('my' AS varchar(200)) AS c6
INTO wide_index
FROM sys.columns AS a, sys.columns AS b, sys.columns AS c
CREATE CLUSTERED INDEX x ON wide_index(c1)
GO
--Investigate the data if you want
/*
--wide index
SELECT TOP(100) * FROM wide_index
EXEC sp_indexinfo wide_index --Found on my web-site
EXEC sp_help 'wide_index'
--narrow index
SELECT TOP(100) * FROM narrow_index
EXEC sp_indexinfo narrow_index --Found on my web-site
EXEC sp_help 'narrow_index'
*/
--/Setup section
--Create the proc that executes our SQL
EXEC #status 'Create the proc that executes our SQL…'
GO
CREATE OR ALTER PROC run_the_sql
@fragmented varchar(20)
,@rows_to_read int
,@range_iterations int
,@fill_bp char(1) --'y' or 'n'
,@report_frag char(1) = 'n'
AS
DECLARE
@sql nvarchar(1000)
,@sql_condition varchar(1000)
,@bp_wide_mb decimal(9,2)
,@bp_narrow_mb decimal(9,2)
,@range_start int
,@range_end int
,@range_iterations_counter int
,@a int
,@start_time datetime2
,@exec_time_wide_index_usec bigint
,@exec_time_narrow_index_usec bigint
,@parm_definition nvarchar(200)
SET STATISTICS IO OFF
EXEC change_trace_status @state = 'stop'
EXEC change_trace_status @state = 'delete_all_files'
--Do a first execution to get autostats etc out of the way
DBCC FREEPROCCACHE
SET @range_iterations_counter = 1
SET @range_start = 1000
SET @range_end = @range_start + @rows_to_read - 1
SET @parm_definition = '@range_start int, @range_end int'
SET @sql = N'DECLARE @a int SELECT @a = COUNT_BIG(c1) FROM wide_index WHERE c1 BETWEEN @range_start AND @range_end'
EXEC sp_executesql @sql, @parm_definition, @range_start, @range_end
SET @sql = N'DECLARE @a int SELECT @a = COUNT_BIG(c1) FROM narrow_index WHERE c1 BETWEEN @range_start AND @range_end'
EXEC sp_executesql @sql, @parm_definition, @range_start, @range_end
--Empty data cache (buffer pool, BP)
CHECKPOINT
DBCC DROPCLEANBUFFERS
--Run proc to read stuff into BP if requested
IF @fill_bp = 'y'
EXEC fill_bp
--Start the trace
EXEC change_trace_status @state = 'start'
--Do the SELECTs, narrow index
SET @sql = N'DECLARE @a int SELECT @a = COUNT_BIG(c1) FROM narrow_index WHERE c1 BETWEEN @range_start AND @range_end'
SET @range_iterations_counter = 1
SET @range_start = 1000
SET @range_end = @range_start + @rows_to_read - 1
SET @start_time = SYSDATETIME()
WHILE @range_iterations_counter <= @range_iterations
BEGIN
EXEC sp_executesql @sql, @parm_definition, @range_start, @range_end
SET @range_start = @range_start + @rows_to_read
SET @range_end = @range_end + @rows_to_read
SET @range_iterations_counter += 1
END
SET @exec_time_narrow_index_usec = DATEDIFF_BIG(microsecond, @start_time, SYSDATETIME()) / @range_iterations
--Do the SELECTs, wide index
SET @sql = N'DECLARE @a int SELECT @a = COUNT_BIG(c1) FROM wide_index WHERE c1 BETWEEN @range_start AND @range_end'
SET @range_iterations_counter = 1
SET @range_start = 1000
SET @range_end = @range_start + @rows_to_read - 1
SET @start_time = SYSDATETIME()
WHILE @range_iterations_counter <= @range_iterations
BEGIN
EXEC sp_executesql @sql, @parm_definition, @range_start, @range_end
SET @range_start = @range_start + @rows_to_read
SET @range_end = @range_end + @rows_to_read
SET @range_iterations_counter += 1
END
SET @exec_time_wide_index_usec = DATEDIFF_BIG(microsecond, @start_time, SYSDATETIME()) / @range_iterations
EXEC change_trace_status @state = 'stop'
--Show the execution plan statistics
--SELECT @fragmented AS frag_level, * FROM vShowPlans as p WHERE p.db_name_ = DB_NAME() AND text_query LIKE '%wide_index%' OR text_query LIKE '%narrow_index%' ORDER BY text_query
--Keep track of BP usage
SET @bp_wide_mb =
(
SELECT
CAST((COUNT(*) * 8.00) / 1024 AS DECIMAL(9,2)) AS MB
FROM sys.allocation_units AS a
JOIN sys.dm_os_buffer_descriptors AS b
ON a.allocation_unit_id = b.allocation_unit_id
JOIN sys.partitions AS p
ON a.container_id = p.hobt_id
WHERE p.object_id = OBJECT_ID('wide_index')
AND b.database_id = DB_ID()
)
SET @bp_narrow_mb =
(
SELECT
CAST((COUNT(*) * 8.00) / 1024 AS DECIMAL(9,2)) AS MB
FROM sys.allocation_units AS a
JOIN sys.dm_os_buffer_descriptors AS b
ON a.allocation_unit_id = b.allocation_unit_id
JOIN sys.partitions AS p
ON a.container_id = p.hobt_id
WHERE p.object_id = OBJECT_ID('narrow_index')
AND b.database_id = DB_ID()
)
--Wait for trace data to arrive in target
WAITFOR DELAY '00:00:10'
--Get the trace data into our table
SELECT CAST(event_data AS XML) AS StatementData
INTO #myRawXeData
FROM sys.fn_xe_file_target_read_file('C:\R\frag_test*.xel', NULL, NULL, NULL);
--Done with trace file, delete it
EXEC change_trace_status @state = 'delete_all_files';
--Transform raw trace data into our measures table
WITH t AS(
SELECT
StatementData.value('(event/data[@name="duration"]/value)[1]','bigint') AS duration_microsec
,StatementData.value('(event/data[@name="cpu_time"]/value)[1]','bigint') AS cpu_microsec
,StatementData.value('(event/data[@name="physical_reads"]/value)[1]','bigint') AS physical_reads
,StatementData.value('(event/data[@name="logical_reads"]/value)[1]','bigint') AS logical_reads
,StatementData.value('(event/data[@name="statement"]/value)[1]','nvarchar(500)') AS statement_
--,StatementData.value('(event[1]/@timestamp)','datetime') AS timestamp_
FROM #myRawXeData AS evts
WHERE StatementData.value('(event/data[@name="statement"]/value)[1]','nvarchar(500)') LIKE '%index WHERE c1%'
--ORDER BY timestamp_
),
t2 AS (
SELECT
CASE WHEN t.statement_ LIKE '%wide_index%' THEN 'wide_index' ELSE 'narrow_index' END AS index_width
,CASE @fragmented WHEN 'high_frag_level' THEN 'y' ELSE 'n' END AS fragmented
,duration_microsec
,CASE WHEN t.statement_ LIKE '%wide_index%' THEN @exec_time_wide_index_usec ELSE @exec_time_narrow_index_usec END AS usec_clock
,cpu_microsec
,physical_reads
,logical_reads
,CASE WHEN t.statement_ LIKE '%wide_index%' THEN @bp_wide_mb ELSE @bp_narrow_mb END AS mb_cache
FROM t)
INSERT INTO measures(rows_to_read, index_width, fragmented, usec_xe, usec_clock, cpu_microsec, physical_reads, logical_reads, mb_cache)
SELECT @rows_to_read, index_width, fragmented, duration_microsec, usec_clock, cpu_microsec, physical_reads, logical_reads, mb_cache
FROM t2;
--Report fragmentation level, if requested
IF @report_frag = 'y'
--Note size of index and frag level, should be comparative between executions
SELECT
OBJECT_NAME(s.object_id) AS table_name
,s.index_type_desc
,CAST(s.avg_fragmentation_in_percent AS decimal(5,1)) AS frag_level
,s.page_count/1000 AS page_count_1000s
,s.index_depth
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'LIMITED') AS s
WHERE s.index_level = 0 AND s.alloc_unit_type_desc = 'IN_ROW_DATA' AND OBJECT_NAME(s.object_id) IN('narrow_index', 'wide_index')
ORDER BY index_id
GO
--END of proc that executes our SQL
--1: Generate fragmentation in both indexes
--Fragment wide ix
EXEC #status 'Generate fragmentation in wide index…'
UPDATE wide_index SET c6 = REPLICATE('a', 200) WHERE c1 % 20 = 0
UPDATE STATISTICS wide_index WITH FULLSCAN, MAXDOP = 0
--Fragment narrow ix
EXEC #status 'Generate fragmentation in narrow index…'
UPDATE narrow_index SET c2 = REPLICATE('a', 20) WHERE c1 % 100 = 0
UPDATE STATISTICS narrow_index WITH FULLSCAN, MAXDOP = 0
--Configure the instance and database
--Execute this if you want to have a rather full BP, restricts memory to 3 GB
EXEC sp_configure 'max server memory', 3000 RECONFIGURE
--Turn off auto-update statistics
ALTER DATABASE Stackoverflow SET AUTO_UPDATE_STATISTICS OFF
--Turn off parallelism
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 1
--Just for fun, if you want: disable read-ahead (sequential pre-fetch)
--DBCC TRACEON(652, -1)
--Run the queries
DROP TABLE IF EXISTS #myRawXeData
EXEC #status 'Run queries with high frag level…'
--EXEC run_the_sql @fragmented = 'high_frag_level', @rows_to_read = 1, @range_iterations = 100, @fill_bp = 'y', @report_frag = 'y'
EXEC run_the_sql @fragmented = 'high_frag_level', @rows_to_read = 10000, @range_iterations = 100, @fill_bp = 'y', @report_frag = 'n'
EXEC run_the_sql @fragmented = 'high_frag_level', @rows_to_read = 100000, @range_iterations = 100, @fill_bp = 'y', @report_frag = 'n'
--2: Defrag the indexes with a fillfactor set to make same size as when fragmented
EXEC sp_configure 'max server memory', 26357 RECONFIGURE
EXEC #status 'Eliminate fragmentation in wide index…'
ALTER INDEX x ON wide_index REBUILD WITH (FILLFACTOR = 48, MAXDOP = 0)
EXEC #status 'Eliminate fragmentation in narrow index…'
ALTER INDEX x ON narrow_index REBUILD WITH (FILLFACTOR = 50, MAXDOP = 0)
EXEC sp_configure 'max server memory', 3000 RECONFIGURE
--Run the queries
DROP TABLE IF EXISTS #myRawXeData
EXEC #status 'Run queries with low frag level…'
--EXEC run_the_sql @fragmented = 'low_frag_level', @rows_to_read = 1, @range_iterations = 100, @fill_bp = 'y', @report_frag = 'y'
EXEC run_the_sql @fragmented = 'low_frag_level', @rows_to_read = 10000, @range_iterations = 100, @fill_bp = 'y', @report_frag = 'n'
EXEC run_the_sql @fragmented = 'low_frag_level', @rows_to_read = 100000, @range_iterations = 100, @fill_bp = 'y', @report_frag = 'n'
-----------------------------------------------------------------------------------
--Reset configurations
EXEC sp_configure 'cursor threshold', -1
EXEC sp_configure 'max server memory', 26357
RECONFIGURE
ALTER DATABASE Stackoverflow SET AUTO_UPDATE_STATISTICS ON
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0
DBCC TRACEOFF(652, -1)
GO
-----------------------------------------------------------------------------------
--Run below manually and investigate the output
--Raw data from the trace
SELECT * FROM measures ORDER BY rows_to_read, index_width, fragmented
--Average the data.
SELECT
m.rows_to_read
,m.index_width
,m.fragmented
--,AVG(m.usec_xe) AS usec_xe
,AVG(m.usec_clock) AS usec_clock
,AVG(m.mb_cache) AS mb_cache
,AVG(m.physical_reads) AS physical_reads
,AVG(m.logical_reads) AS logical_reads
--,AVG(m.cpu_microsec) AS cpu_microsec --I didn't find this relevant, hence the exclusion
FROM measures AS m
GROUP BY m.rows_to_read, m.index_width, m.fragmented
ORDER BY index_width, rows_to_read, fragmented;
-----------------------------------------------------------------------------------
--Cleanup
/*
DROP TABLE IF EXISTS narrow_index
DROP TABLE IF EXISTS myXeData
DROP TABLE IF EXISTS myXeData2
DROP TABLE IF EXISTS bp_usage
*/
Measuring things can be difficult. I have been painfully reminded of that with my attempts to measure whether fragmentation matters with new hardware. I created a test script in which I read data seeking the index (following the linked list of the leaf level of the index).
My thoughts were that “jumping back and forth” doesn’t matter with modern I/O subsystems. But perhaps read-ahead reads more (unnecessary) data into cache and less useful data remains in memory because of this?
In my first post, came to the conclusion that it didn’t matter for execution time, but I noticed that lots of memory was brought into cache when the index was fragmented. There’s some background info in there: http://sqlblog.karaszi.com/does-index-fragmentation-matter/ .
In my second blog post, I focused on how much memory was brought into cache. And I found that when the index was fragmented, I noticed 1000 times more memory usage. Surely, read-ahead, cannot cause this!? http://sqlblog.karaszi.com/index-fragmentation-part-2/
Because of the absurde figures, I had to dig deeper. Paul White told me about a lesser known optimization where SQL server will do “large I/O” (my own term for this) if you have plenty of unused memory. Instead of reading single pages, it reads whole extents. This makes sense, warming up the cache. https://blogs.msdn.microsoft.com/ialonso/2011/12/09/the-read-ahead-that-doesnt-count-as-read-ahead/
But still, that can’t account for 1000 times more memory usage for a fragmented index. I can live with 5-10 times, but not 1000 times. And then Simon Sabin pointed out the obvious: auto-update of statistics! My first set of SELECTs was done after a updating a bunch of rows (so to fragment the index), and that triggered auto update statistics (bringing the whole index into memory). Mystery solved.
My findings
As I said, I found it extremely difficult to measure this. Things happens in the machine which can muddle the results. I did the test over and over again. Looking at both details and averages. My conclusion is that with same amount of pages, you will see a pretty marginal effect of fragmentation. “Marginal” is in the eye of the beholder, though. More details further down. Please read my earlier posts, especially the first one for background information.
What about page fullness?
To be honest, I find this to be a much more interesting aspect. I’d like to split this into two sub-sections. Increasing and “random” index.
Increasing index
This can be like an identity or ever increasing datetime column (think for instance order_date). This will not become fragmented from INSERTS and assuming that you don’t delete “every other row”, then you will end up with a nice unfragmented index with a high degree of page fullness. If you rebuild it with a fillfactor of 100%, you have just wasted resources. If you rebuild it with a lower fillfactor, you also waste space and cause SQL Server to read more data – causing worse performance.
Random index
By this I mean index where the data distribution is all over the place. For instance an index on the LastName column. As you insert data, pages are split and you end up with a fillfactor of about 75% (which is in between a half-full and a full page). If you rebuild it with a similar fillfactor, you didn’t gain anything. If you rebuild it with a high fillfactor, then the following activity in your database will generate a high number of page splits. It seems reasonable to let it be, accepting a fillfactor of about 75% and accept a page split every now and then.
But we also delete data!
Do you? Really? OK, let us say that you do. What is the delete pattern? And the degree of deletes? How does this spread over your particular index? Deleting old data over some ever increasing index will just deallocate those pages. Deleting data which doesn’t match with the index key (rows deleted are spread all over the index) will leave empty space. This will be re-used as you insert new rows. But if you delete a lot of data, then you will have a low degree of page fullness. IMO, this is a rather unusual situation and should warrant a manually triggered index maintenance, in contrast to rebuilding indexes every week or so. (And don’t get me started on heaps, but surely you don’t have those…? I once had a SELECT of all rows for a table with only 3000 rows, which took minutes. It had allocated more extents than number of rows in the table. Rebuild it, and it took, of course, sub-second. Needless to say, this didn’t stay as a heap for long. And no, the table wasn’t wide, at all.)
Bottom line?
Being who I am, I don’t want to draw too hard conclusions from some tests and reasoning. But I must say that I doubt the value of regular index defrag – assuming you are on some modern I/O subsystem, of course. I think that folks focus on index defrag and forget about statistics. I like to provide the optimizer with as high-quality statistics as possible. Sure, index rebuild will give you new statistics. But if you condition it based on fragmentation, then you end up with not rebuilding a bunch of indexes and have stale statistics. Auto update statistics is OK, but you have to modify a decent amount of data before it kicks in. And when it kicks in, the user waits for it. Unless you do async update…. But I digress. Statistics management is a topic of its own. My point is that you probably don’t want to lose track of statistics management because you keep staring as index fragmentation.
My tests – details
Check out this section if you are curious of how I did it, want to see the numbers and perhaps even do tests of your own. I welcome constructive criticism which can be weaknesses etc in my test scripts. Or perhaps different interpretations of the outcome!
The basic flow is:
Create a proc which does bunch of reads to fill the buffer pool with data.
Create some other supporting stuff, like trace definition, trace control procedure etc.
Grow the data and log files for the Stackoverflow (10 GB) database.
Create table to hold my measures.
Create the narrow_index table which is a table with a clustered index which is narrow. A row is some 40 bytes (very rough calculation off the top of my head).
Create the wide_index is a table with a clustered index which is wider – some 340 bytes.
Set max server memory to 1 GB.
Turn off auto-update statistics.
Create the proc that will do the tests.
Generate fragmentation in both indexes/tables.
The narrow table has 20,000,000 rows and is about 970 MB in size.
The wide table has 10,000,000 rows and is about 6.8 GB in size.
Run the proc that does the test with 1 row selectivity.
Run the proc that does the test with 10000 rows selectivity.
Run the proc that does the test with 100000 rows selectivity.
Each test runs 99 SELECTs, spread over the data (so not to read the same row).
Average the result, into a table named resx.
I did 4 such iterations, so I have the tables res1, res2, res3 and res4.
Check the numbers from these tables and see if they correspond reasonably. They did.
Average the results from these four table to get the end results.
The procedure which executes the SELECTS and captures the measures has this basic flow
Stop the (XE) trace if it is running.
Delete all old trace files.
Do a first SELECT to get rid of auto-stats (yeah, I disabled it, but just in case).
Empty the cache.
Reads lots of other data into cache.
Start the trace
Do the SELECT, in a loop, reading as many rows as requested (param to the proc), as many times as requested (another param to the proc). Don’t read the same data over and over again. This is done both for the narrow and wide table/index.
Capture memory usage for each table (buffer pool usage).
Get the trace raw data into a temp table.
Parse the trace data/above table using XQuery into the measures table.
Ie., we now have one row for each SELECT with a bunch of measures.
The measures
Microseconds as captured with the Extended Event trace.
Microseconds as “wall clock time”. I.e., capture datetime before the loop in a variable and calculate microseconds after the loop into a variable, divided by number of executions. This value will then be the same for each execution in the loop. I want to have two different ways to calculate execution time, as a sanity check. In the end, they corresponded pretty well.
How much data of the table was brought into cache.
Physical reads. This is of lower interest, since read-ahead will muddle the result.
Logical reads. This is more interesting and can among other things be used to check t at we read about the same number of pages for the fragmented and for the non-fragmented index. Which we should – they have the same fillfactor!
CPU microseconds. I didn’t find this very interesting.
Outcome
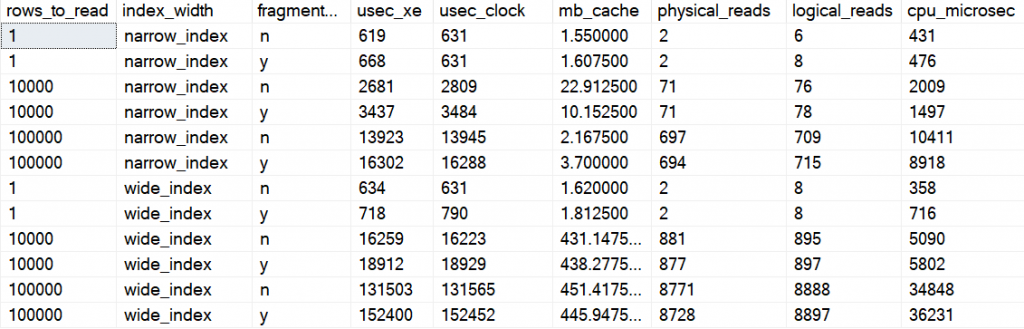
I ignored the reading of 1 row, this shouldn’t differ, and the small difference I found I attribute to imperfections in the ability to capture exact numbers.
When reading 1000 rows for the narrow table, about 75 pages, the fragmented index was about 30% slower.
When reading some 700-900 pages (100,000 rows for the narrow table and 10,000 rows for the wide table) the fragmented table was about 16-17 % slower.
When reading about 9,000 pages (100,000 rows for the wide table), the fragmented index was about 15% slower.
Here are the averages, one row per execution (remember that I did 99 SELECTs in a loop, so this is the average of those):
Narrow indexWide index
And here is the average of those averages
The code
------------------------------------------------------------------------------------------------
--Measure cost of fragmentation in terms of execution time and memory usage
--Tibor Karaszi, 2019
--Requires the Stackoverflow database. I was using the 10 GB version.
------------------------------------------------------------------------------------------------
SET NOCOUNT ON
------------------------------------------------------------------------------------------------
--Setup section
------------------------------------------------------------------------------------------------
USE StackOverflow
GO
--Proc to fill buffer pool, reads lots of data, takes a while to execute, especially if on spinning disk
CREATE OR ALTER PROC fill_bp
AS
DECLARE @a bigint
SET @a = (SELECT AVG(CAST(PostId AS bigint)) FROM Comments)
SET @a = (SELECT AVG(CAST(CommentCount AS bigint)) FROM Posts)
SET @a = (SELECT AVG(CAST(PostId AS bigint)) FROM Comments)
SET @a = (SELECT AVG(CAST(VoteTypeId AS bigint)) FROM Votes)
SET @a = (SELECT AVG(CAST(PostId AS bigint)) FROM Comments)
SET @a = (SELECT AVG(CAST(VoteTypeId AS bigint)) FROM Votes)
SET @a = (SELECT AVG(CAST(VoteTypeId AS bigint)) FROM Votes)
GO
--Disable IAM order scan, so we know that SQL Server will follow the linked list
--See https://sqlperformance.com/2015/01/t-sql-queries/allocation-order-scans
EXEC sp_configure 'cursor threshold', 1000000 RECONFIGURE
GO
--Proc to change trace status
CREATE OR ALTER PROC change_trace_status
@state varchar(50) --start, stop, delete_all_files
AS
IF @state = 'start'
BEGIN
IF NOT EXISTS (SELECT * FROM sys.dm_xe_sessions WHERE name = 'frag_test')
ALTER EVENT SESSION frag_test ON SERVER STATE = START
END
IF @state = 'stop'
BEGIN
IF EXISTS (SELECT * FROM sys.dm_xe_sessions WHERE name = 'frag_test')
ALTER EVENT SESSION frag_test ON SERVER STATE = STOP
END
--Delete XE file, using xp_cmdshell (ugly, I know)
IF @state = 'delete_all_files'
BEGIN
EXEC sp_configure 'xp_cmdshell', 1 RECONFIGURE WITH OVERRIDE
EXEC xp_cmdshell 'DEL R:\frag_test*.xel', no_output
EXEC sp_configure 'xp_cmdshell', 0 RECONFIGURE WITH OVERRIDE
END
/*
EXEC change_trace_status @state = 'start'
EXEC change_trace_status @state = 'stop'
EXEC change_trace_status @state = 'delete_all_files'
*/
GO
--Drop and create event session to keep track of execution time
EXEC change_trace_status @state = 'stop'
WAITFOR DELAY '00:00:01'
IF EXISTS (SELECT * FROM sys.server_event_sessions WHERE name = 'frag_test')
DROP EVENT SESSION frag_test ON SERVER
EXEC change_trace_status @state = 'delete_all_files'
CREATE EVENT SESSION frag_test ON SERVER
ADD EVENT sqlserver.sp_statement_completed()
ADD TARGET package0.event_file(SET filename=N'R:\frag_test')
WITH (MAX_DISPATCH_LATENCY=10 SECONDS)
GO
--Create proc to report progress
CREATE OR ALTER PROC #status
@msg varchar(200)
AS
RAISERROR(@msg, 10, 1) WITH NOWAIT
GO
--Grow the data and log files for StackOverflow database.
EXEC #status 'Grow the data and log files for StackOverflow database...'
IF EXISTS( SELECT size * 8/(1024*1024), *
FROM sys.database_files
WHERE name = N'StackOverflow2010' AND size * 8/(1024*1024) < 30)
ALTER DATABASE [StackOverflow] MODIFY FILE ( NAME = N'StackOverflow2010', SIZE = 30GB )
IF EXISTS( SELECT size * 8/(1024*1024), *
FROM sys.database_files
WHERE name = N'StackOverflow2010_log' AND size * 8/(1024*1024) < 15)
ALTER DATABASE [StackOverflow] MODIFY FILE ( NAME = N'StackOverflow2010_log', SIZE = 15GB )
GO
--Table to hold output
DROP TABLE IF EXISTS measures
CREATE TABLE measures (
id int identity(1,1) PRIMARY KEY NOT NULL
,rows_to_read int NOT NULL
,index_width varchar(20) NOT NULL
,fragmented varchar(2) NOT NULL
,usec_xe bigint NOT NULL
,usec_clock bigint NOT NULL
,cpu_microsec bigint NOT NULL
,physical_reads bigint NOT NULL
,logical_reads bigint NOT NULL
,mb_cache decimal(9,2) NOT NULL
);
--Create the table for the narrow index
EXEC #status 'Setup section. Create table with narrow index...'
DROP TABLE IF EXISTS narrow_index
--Adjust numbers. 20,000,000 rows means about 970 MB in the end
SELECT TOP(1000*1000*20) ROW_NUMBER() OVER( ORDER BY (SELECT NULL)) AS c1, CAST('Hello' AS varchar(80)) AS c2
INTO narrow_index
FROM sys.columns AS a, sys.columns AS b, sys.columns AS c
CREATE CLUSTERED INDEX x ON narrow_index(c1)
--Create the table for the wide index
EXEC #status 'Setup section. Create table with wide index...'
DROP TABLE IF EXISTS wide_index
--Adjust numbers. 10,000,000 rows means about 6.8 GB in the end
SELECT
TOP(1000*1000*10) ROW_NUMBER() OVER( ORDER BY (SELECT NULL)) AS c1
,CAST('Hi' AS char(80)) AS c2
,CAST('there' AS char(80)) AS c3
,CAST('I''m' AS char(80)) AS c4
,CAST('on' AS char(80)) AS c5
,CAST('my' AS varchar(200)) AS c6
INTO wide_index
FROM sys.columns AS a, sys.columns AS b, sys.columns AS c
CREATE CLUSTERED INDEX x ON wide_index(c1)
GO
------------------------------------------------------------------------------------------------
--Investigate the data if you want
/*
--wide index
SELECT TOP(100) * FROM wide_index
EXEC sp_indexinfo wide_index --Found on my web-site
EXEC sp_help 'wide_index'
--narrow index
SELECT TOP(100) * FROM narrow_index
EXEC sp_indexinfo narrow_index --Found on my web-site
EXEC sp_help 'narrow_index'
*/
--Execute this if you want to have a rather full BP, restricts memory to 1 GB
EXEC sp_configure 'max server memory', 1000 RECONFIGURE
--Turn off auto-update statistics
ALTER DATABASE Stackoverflow SET AUTO_UPDATE_STATISTICS OFF
------------------------------------------------------------------------------------------------
--/Setup section
------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------
--Create the proc that executes our SQL
EXEC #status 'Create the proc that executes our SQL...'
GO
CREATE OR ALTER PROC run_the_sql
@fragmented varchar(20)
,@rows_to_read int
,@range_iterations int
,@fill_bp char(1) --'y' or 'n'
,@report_frag char(1) = 'n'
AS
DECLARE
@sql varchar(1000)
,@sql_condition varchar(1000)
,@bp_wide_mb decimal(9,2)
,@bp_narrow_mb decimal(9,2)
,@range_start int
,@range_iterations_counter int
,@a int
,@start_time datetime2
,@exec_time_wide_index_usec bigint
,@exec_time_narrow_index_usec bigint
EXEC change_trace_status @state = 'stop'
EXEC change_trace_status @state = 'delete_all_files'
--Do a first execution to get autostats etc out of the way
DBCC FREEPROCCACHE
SET @range_iterations_counter = 1
SET @range_start = 1000
SET @a = (SELECT COUNT_BIG(c1) AS c1_count FROM wide_index WHERE c1 BETWEEN @range_start AND (@range_start + @rows_to_read - 1))
SET @a = (SELECT COUNT_BIG(c1) AS c1_count FROM narrow_index WHERE c1 BETWEEN @range_start AND (@range_start + @rows_to_read - 1))
--Empty data cache (buffer pool, BP)
CHECKPOINT
DBCC DROPCLEANBUFFERS
--Run proc to read stuff into BP if requested
IF @fill_bp = 'y'
EXEC fill_bp
EXEC change_trace_status @state = 'start'
--Do the SELECTs, narrow index
SET @range_iterations_counter = 1
SET @range_start = 1000
SET @start_time = SYSDATETIME()
WHILE @range_iterations_counter <= @range_iterations
BEGIN
SET @a = (SELECT COUNT_BIG(c1) AS c1_count FROM narrow_index WHERE c1 BETWEEN @range_start AND (@range_start + @rows_to_read - 1))
SET @range_start = @range_start + 100000
SET @range_iterations_counter += 1
END
SET @exec_time_narrow_index_usec = DATEDIFF_BIG(microsecond, @start_time, SYSDATETIME()) / @range_iterations
--Do the SELECTs, wide index
SET @range_iterations_counter = 1
SET @range_start = 1000
SET @start_time = SYSDATETIME()
WHILE @range_iterations_counter <= @range_iterations
BEGIN
SET @a = (SELECT COUNT_BIG(c1) AS c1_count FROM wide_index WHERE c1 BETWEEN @range_start AND (@range_start + @rows_to_read - 1))
SET @range_start = @range_start + 100000
SET @range_iterations_counter += 1
END
SET @exec_time_wide_index_usec = DATEDIFF_BIG(microsecond, @start_time, SYSDATETIME()) / @range_iterations
EXEC change_trace_status @state = 'stop'
--Keep track of BP usage
SET @bp_wide_mb =
(
SELECT
CAST((COUNT(*) * 8.00) / 1024 AS DECIMAL(9,2)) AS MB
FROM sys.allocation_units AS a
JOIN sys.dm_os_buffer_descriptors AS b
ON a.allocation_unit_id = b.allocation_unit_id
JOIN sys.partitions AS p
ON a.container_id = p.hobt_id
WHERE p.object_id = OBJECT_ID('wide_index')
AND b.database_id = DB_ID()
)
SET @bp_narrow_mb =
(
SELECT
CAST((COUNT(*) * 8.00) / 1024 AS DECIMAL(9,2)) AS MB
FROM sys.allocation_units AS a
JOIN sys.dm_os_buffer_descriptors AS b
ON a.allocation_unit_id = b.allocation_unit_id
JOIN sys.partitions AS p
ON a.container_id = p.hobt_id
WHERE p.object_id = OBJECT_ID('narrow_index')
AND b.database_id = DB_ID()
)
--Wait for trace data to arrive in target
WAITFOR DELAY '00:00:10'
--Get the trace data into our table
SELECT CAST(event_data AS XML) AS StatementData
INTO #myRawXeData
FROM sys.fn_xe_file_target_read_file('R:\frag_test*.xel', NULL, NULL, NULL);
--Done with trace file, delete it
EXEC change_trace_status @state = 'delete_all_files';
--Transform raw trace data into our measures table
WITH t AS(
SELECT
StatementData.value('(event/data[@name="duration"]/value)[1]','bigint') AS duration_microsec
,StatementData.value('(event/data[@name="cpu_time"]/value)[1]','bigint') AS cpu_microsec
,StatementData.value('(event/data[@name="physical_reads"]/value)[1]','bigint') AS physical_reads
,StatementData.value('(event/data[@name="logical_reads"]/value)[1]','bigint') AS logical_reads
,StatementData.value('(event/data[@name="statement"]/value)[1]','nvarchar(500)') AS statement_
FROM #myRawXeData AS evts
WHERE StatementData.value('(event/data[@name="statement"]/value)[1]','nvarchar(500)') LIKE '%index WHERE c1%'
),
t2 AS (
SELECT
CASE WHEN t.statement_ LIKE '%wide_index%' THEN 'wide_index' ELSE 'narrow_index' END AS index_width
,CASE @fragmented WHEN 'high_frag_level' THEN 'y' ELSE 'n' END AS fragmented
,duration_microsec
,CASE WHEN t.statement_ LIKE '%wide_index%' THEN @exec_time_wide_index_usec ELSE @exec_time_narrow_index_usec END AS usec_clock
,cpu_microsec
,physical_reads
,logical_reads
,CASE WHEN t.statement_ LIKE '%wide_index%' THEN @bp_wide_mb ELSE @bp_narrow_mb END AS mb_cache
FROM t)
INSERT INTO measures(rows_to_read, index_width, fragmented, usec_xe, usec_clock, cpu_microsec, physical_reads, logical_reads, mb_cache)
SELECT @rows_to_read, index_width, fragmented, duration_microsec, usec_clock, cpu_microsec, physical_reads, logical_reads, mb_cache
FROM t2;
--Report fragmentation level, if requested
IF @report_frag = 'y'
--Note size of index and frag level, should be comparative between executions
SELECT
OBJECT_NAME(object_id) AS table_name
,index_type_desc
,CAST(avg_fragmentation_in_percent AS decimal(5,1)) AS frag_level
,page_count/1000 AS page_count_1000s
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'LIMITED')
WHERE index_level = 0 AND alloc_unit_type_desc = 'IN_ROW_DATA' AND OBJECT_NAME(object_id) IN('narrow_index', 'wide_index')
ORDER BY index_id
GO
------------------------------------------------------------------------------------------------
--1: Generate fragmentation in both indexes
--Fragment wide ix
EXEC #status 'Generate fragmentation in wide index...'
UPDATE wide_index SET c6 = REPLICATE('a', 200) WHERE c1 % 20 = 0
UPDATE STATISTICS wide_index WITH FULLSCAN
--Fragment narrow ix
EXEC #status 'Generate fragmentation in narrow index...'
UPDATE narrow_index SET c2 = REPLICATE('a', 20) WHERE c1 % 100 = 0
UPDATE STATISTICS narrow_index WITH FULLSCAN
--Run the queries
EXEC #status 'Run queries with high frag level...'
EXEC run_the_sql @fragmented = 'high_frag_level', @rows_to_read = 1, @range_iterations = 99, @fill_bp = 'y'
EXEC run_the_sql @fragmented = 'high_frag_level', @rows_to_read = 10000, @range_iterations = 99, @fill_bp = 'y'
EXEC run_the_sql @fragmented = 'high_frag_level', @rows_to_read = 100000, @range_iterations = 99, @fill_bp = 'y'
-----------------------------------------------------------------------------------
--2: no frag in either index, fillfactor set to make same size as when fragmented
EXEC #status 'Eliminate fragmentation in wide index...'
ALTER INDEX x ON wide_index REBUILD WITH (FILLFACTOR = 48)
EXEC #status 'Eliminate fragmentation in narrow index...'
ALTER INDEX x ON narrow_index REBUILD WITH (FILLFACTOR = 50)
--Run the queries
EXEC #status 'Run queries with low frag level...'
EXEC run_the_sql @fragmented = 'low_frag_level', @rows_to_read = 1, @range_iterations = 99, @fill_bp = 'y'
EXEC run_the_sql @fragmented = 'low_frag_level', @rows_to_read = 10000, @range_iterations = 99, @fill_bp = 'y'
EXEC run_the_sql @fragmented = 'low_frag_level', @rows_to_read = 100000, @range_iterations = 99, @fill_bp = 'y'
-----------------------------------------------------------------------------------
-----------------------------------------------------------------------------------
--Reset
EXEC sp_configure 'cursor threshold', -1
EXEC sp_configure 'max server memory', 2147483647
RECONFIGURE
GO
-----------------------------------------------------------------------------------
-----------------------------------------------------------------------------------
--Run below manually and investigate the output
--Raw data from the trace
SELECT * FROM measures ORDER BY rows_to_read, index_width, fragmented
--Average the data.
--Note that I ran this script 4 times and used INTO here to create 4 tables. Res1, res2, res3, and res4.
SELECT
m.rows_to_read
,m.index_width
,m.fragmented
,AVG(m.usec_xe) AS usec_xe
,AVG(m.usec_clock) AS usec_clock
,AVG(m.mb_cache) AS mb_cache
,AVG(m.physical_reads) AS physical_reads
,AVG(m.logical_reads) AS logical_reads
,AVG(m.cpu_microsec) AS cpu_microsec
-- INTO res4 --if you want to persist the results
FROM measures AS m
GROUP BY m.rows_to_read, m.index_width, m.fragmented
ORDER BY index_width, rows_to_read, fragmented;
--Check the details from the averages of each execution
WITH x AS(
SELECT 1 AS ord, * FROM res1
UNION ALL
SELECT 2 AS ord, * FROM res2
UNION ALL
SELECT 3 AS ord, * FROM res3
UNION ALL
SELECT 4 AS ord, * FROM res4
)
SELECT * FROM x
WHERE index_width = 'narrow_index'
ORDER BY index_width, rows_to_read, fragmented, ord;
--Average the averages
WITH x AS(
SELECT 1 AS ord, * FROM res1
UNION ALL
SELECT 2 AS ord, * FROM res2
UNION ALL
SELECT 3 AS ord, * FROM res3
UNION ALL
SELECT 4 AS ord, * FROM res4
)
SELECT
m.rows_to_read
,m.index_width
,m.fragmented
,AVG(m.usec_xe) AS usec_xe
,AVG(m.usec_clock) AS usec_clock
,AVG(m.mb_cache) AS mb_cache
,AVG(m.physical_reads) AS physical_reads
,AVG(m.logical_reads) AS logical_reads
,AVG(m.cpu_microsec) AS cpu_microsec
FROM x AS m
GROUP BY m.rows_to_read, m.index_width, m.fragmented
ORDER BY index_width, rows_to_read, fragmented;
-----------------------------------------------------------------------------------
-----------------------------------------------------------------------------------
--Cleanup
/*
DROP TABLE IF EXISTS narrow_index
DROP TABLE IF EXISTS myXeData
DROP TABLE IF EXISTS myXeData2
DROP TABLE IF EXISTS bp_usage
*/
This post is about a topic that everybody who uses columnstore should think about. And that is about ordering. The analogy I will be using is flawed in so many ways, but it help to get my point through. I hope.
You now say to yourself that columnstore indexes aren’t sorted, so what am I yapping about? Hear me out.
Imagine that I will organize my underpants. I don’t know if the word underpants is, sort of, reserved for female underwear, but I’ll use that term anyhow. (I’m Swedish and don’t get all nuances of the English language.) Also Imagine that I have a bunch of drawers. Say I fit about 50 underpants in each drawer and I have some 1000 underpants. How should I do this? The drawer is the rowgroup but it would be ridiculous to say you have about 1,000,000 underpants in each drawer (the approx number of rows in a col-store rowgroup). The 1000 underpants is the number of rows in my “underpants” table, and even 1000 underpants seems like a ridiculous number. Anyhow…
Now imagine that I’m very picky with what underpants I’m wearing. The type (boxer, briefs, string, and whatnot), color, size, material etc. So how do I decide what underpants goes into each drawer? I could just shove them in there without much though about that process. I think that is how many handle their col-store indexes.
Also imagine that we have a device that register attributes about the underpants as we add them to the drawer. Lets call this device u47. So, the u47 will label the drawer with some info on what briefs are in there. Like range of sizes (xxs to xxl). OK, strange perhaps but say that my size vary a lot over time. And also range of colors. And range of models. You have now figured ut that I like to classify things in ranges. I.e., this particular drawer has m-xl; white-green, string to briefs and cotton to satin. This would be the meta-data that SQL Server has for each rowgroup/segment, as seen in sys.column_store_segments.
Lets go back to how you populated your drawers. Did you just shove the underpants there? Then you probably have close to the full range of all attribute values in each drawer. I.e., every drawer has underpants of all sizes, all colors, etc.
Now I want to wear all black underpants. Let’s say I’m a bit strange in that sense. Since there are black underpants in all drawers, it will take a while to find them all. I have to go through each drawer. Or I want all satin underpants. Or perhaps all medium size black satin briefs. I still have to go through each drawer.
But what if I took the time to sort the underpants before adding them to the drawers? I can only sort them by one attribute. I should pick the one attribute that I most often have in my “what underpants should I use today?” decision process. You achieve this by having a row-clustered index on that column when building the col-store clustered index and build the col-store index using WITH DROP_EXISTING. Also, instead of having my friends over and each of us grab some underwear and add them to each person’s drawer (parallelism when building the index), I would do this myself. Yes, that means MAXDOP = 1. Without it, say you have 4 threads/friends and sort by size when when populating the drawers/building the index, then you have 4 drawers with xs-s, 4 drawers with m-l, etc.
For non-clustered col-store index, it would be enough with a non-clustered index that covers the clustered index when converting it from row to col-store index (DROP_EXISTING).
The underpants inside the drawer isn’t sorted; this is a col-store index we’re talking about, remember? But, you might have some fancy vacuum-tech that allow you to fit many underpants in each drawer (the various columnstore compression technologies), something you probably ordered when you bought the u47, btw.
Now, imagine me walking from the shower to my dressing room and thinking about how to find the underpants of today. I.e., the execution plan. “Today, I want to wear underpants based on color, size and material – model doesn’t matter”. I can’t say what drawers to go through, since that information isn’t available at this stage. It is a run-time decision to do drawer-elimination based on the notes on each drawer (what ranges it contains for each attribute). I.e., rowgroup/segment elimination is a run-time decision.
The underwear will only be partitioned over the drawers in an effective manner for one attribute, the one I sorted them by before populating my drawers. If that is size, then one drawer has only xs, another has only x, etc. But the “xs drawer” has all range of colors, materials etc. There might be some correlation between attributes (like rubber underpants tend to be black), but that correlation isn’t usable for us.
How would row indexes fit in this analogy? You have a bunch of post-it notes with which you build a tree-like structure that you lay out on the floor. You use this tree (over size, for instance) to navigate to the ones you are interested in (medium size for instance), and finally you reach the sub-section in the drawer. You can have several such trees, for various attributes, of course. But, the smart vacuum-tech you bought with the u47 isn’t available for these indexes. If you are very selective (remember the rubber pants?), then you can very quickly find that pair using the tree structure. But it is quicker to find all black underpants using the col-store index because you have many of those and the vacuum-tech allow you to fit so many in each drawer.
And the vacuum-tech also magically allow you to put on as many as some 900 pairs of underpants as a time. Remember that I want to wear all my black underpants. This is batch-mode in the execution plan.. (Rumors has it that we at the end of 2019 will have the option to put on more then one pair at a time even without this magical vacuum tech. That would be batch mode on row-store. We’ll see. )
The bottom line? Think about how the data is sorted when building your col-store indexes and consider rebuilding them if your loading/modification routines causes them to degrade over time. Oh, I should add that you shouldn’t mess about with col-store indexes without having Niko’s blog post series handy and also have read Hugo’s series first.
Disclaimer 1: I don’t own any rubber underpants.
Disclaimer 2: If I did own any rubber underpants, I would still have disclaimer 1 in there…
You might know that statistics can have a high impact on performance. As you add, remove and modify data, the statistics will be more and more outdated.
Sure, there’s the database option that updates statistics automatically, but it is a bit … rough. For a table with 10,000,000 rows, you have to modify 2,000,000 rows prior to 2016 (20%) and 100,000 rows as of 2016 with db compat level 2016 (SQRT(1000*@rows)). Also, when auto-update stats kicks in, it will sample the underlying data, in order for it not to take too long etc.
Many of us use Ola Hallengren’s excellent maintenance solution. I’m sure that some of us have our own favorite modifications we do to the jobs that the installation scrips creates for us. My point here is that the installation script do not update statistics by default. Here’s how job step in the “IndexOptimize – USER_DATABASES” job look like on my SQL Server 2017 instance. All by default:
The default value for the @UpdateStatistics parameter is NULL which means “Do not perform statistics maintenance” See this page for reference.
So, by using the defaults, you end up defragmenting your indexes (which might not give you that much nowadays, considering that there isn’t that much of a difference between random and sequential I/O on modern disk subsystems). For some of the indexes that you defragment, you will get new statistics as a by-product. Those are the indexes that you rebuild – rebuild is internally creating a new index and the dropping the old one. But you likely have many indexes that don’t reach the 30% fragmentation threshold. And consider indexes over a key which is steadily increasing or decreasing. Inserting new rows will not cause fragmentation, but the statistics will become out-of-date.
What to do? Easy, just add a new job in which you call the IndexOptimize procedure with options to update all statistics where at least one row has been modified. Ola even has such example on his web-site, Example D. Here it is, I just added a parameter to log the commands to the CommandLog table:
Schedule above as you wish. I prefer to do it every early morning if I can. But your circumstances like database size, how the data is modified etc will influence the frequency.
Another option is toe modify the existing “IndexOptimize – USER_DATABASES” job and just add below. This will both defrag your indexes and also update statistics.
@UpdateStatistics = 'ALL'
What about Maintenance Plans, you might think? Well, we all know that they aren’t that … smart – which is why we use scripts like Ola’s in the first place. Regarding statistics updates, they will update all stats, regardless of whether any rows at all has been modified since last time. It is a complete waste of resources to update stats if nothing has changed. Even sp_updatestats is smarter in this regard.
Note: This is in no way a criticism of the maintenance solution that Ola provides. He has no way of knowing our requirements in the job he creates. If the installation script could read our minds, I’m sure that it would schedule the jobs for us as well. OTOH, if Ola could create a T-SQL installation script that could read our minds, then he probably would do something else in the first place. 🙂
Many SQL server installations does regular index rebuild or reorg in order to defragment indexes. One can question how much we really gain by doing this when using modern SANs, SSD, flashdisks, etc. But, that is not the topic for this blog post. What I want to raise with this blog is whether to use ONLINE when rebuilding indexes. Some background first::
With ONLINE = OFF (default), you will be blocked from accessing the data while the index rebuild is being performed. Depending on the type of index, you either get a schema modification lock on the table which prohibits any type of access, or a shared lock which allow reads only.
With ONLINE = ON (requires Enterprise Edition), you get a very brief lock at beginning and end of operation. I will refer to the modes as ONLINE and OFFLINE from now on.
There’s more details to what locks are acquired depending on various factors. Check out https://docs.microsoft.com/en-us/sql/t-sql/statements/alter-index-transact-sql for more info. The point is that ONLINE = ON, allow for users to both read and modify data while the operation is on-going. That is a good thing, right? Well, it comes with a price…
The time it takes to rebuild the index can be substantially longer for ONLINE. Many of us has other things to do with the database during night-time and/or weekends. Yes, these are the typical window in time where we try to find things such as index rebuilds. Say that you do it night-time and it currently take 4 hours. Wouldn’t it be nice if you could cut that time down to 1.5 hours? That would leave more time for imports, massaging of data, CHECKDB and other things you want to do. Sure, you can do it ONLINE, but it will slow down access during the rebuild. Also the more data you modify during the rebuild, the more space you need in tempdb.
My point is to not do ONLINE unless you actually need it. Some system don’t have to be “open” during night-time anyhow. Only you can tell what your requirements are, of course. To get some numbers I decided to create a few indexes on a copy of the FactResellerSalesXL_PageCompressed found in the AdventureworksDW2016 database, and I named that table FactResellerSalesXL. I created a copy without data compression and also without any columnstore index. And then I created a few non-clustered index. Here’s the index and space usage for the table, using my sp_indexinfo (with some columns omitted and others re-arranged):
Not a large table by any means, but it gives us something to play with. And it allowed me to do the rebuilds several times in order to rule out figures out of the ordinary. I tested this both in FULL and SIMPLE recovery. The numbers are average after several executions, minutes : seconds:
FULL recovery
ONLINE: 3:45
OFFLINE: 1:03
SIMPLE recovery
ONLINE: 1:40
OFFLINE: 0:31
I frequently use Ola Hallengren’s scripts for database maintenance. (We all do, right? :-)) The default for Ola’s solution (IndexOptimize) is to do the rebuild ONLINE if possible. Or, to be more specific, the defaults are:
< 5% fragmentation: do nothing
Fragmentation between 5 and 30 %: do REORGANIZE.
Fragmentation over 30%: do REBUILD with ONLINE = ON
I.e., when using Ola’s scripts you will rebuild your indexes ONLINE, assuming you are on Enterprise Edition (or similar). For Maintenance Plans (anybody remember those?), the checkbox for ONLINE is not checked by default.
Bottom line: If you have problems with index rebuilds taking a long time and you don’t need other people accessing the data while this is being done, consider doing it OFFLINE instead. Or perhaps not defragment in the first place? Or, raise the bar for to some 60-70 % so you only defragment the indexes that are really fragmented in the first place.
I frequently see recommendations to regularly run sp_cycle_errorlog, so that the errorlog doesn’t become huge. My main concern with that is that the errorlog contains valuable information.
When I do a health check on a SQL Server machine, I want a few months worth of errorlog information available. I typically use my own scripts for this, available here. Almost every time I go through the errorlog, I find valuable information. Some things you address, like find whatever it is that is attempting to login every minute. Other things you might not have control over, but the information is valuable to have.
So, if you run sp_cycle_errorlog every day or week, you end up with only a week worth, or a few weeks worth of errorlog file information.
Suggestion 1: Increase the number of errorlog files.
You probably want more than 6 history errorlog files. For instance, a client of mine told me that he was about to patch a server a few days before I was to visit that client. That patch procedure resulted in enough re-start of SQL Server so we ended up with only 4 days worth of errorlog files. Yes, this client had the default of 6 historic errorlog files. I typically increase this to 15. You can do this by right-clicking the “SQL Server Logs” folder under “Management” in SSMS. If you want to use T-SQL, you can use xp_instance_regwrite, as in:
Suggestion 2: Set a limit for the size of the errorlog file.
But what about the size? Say that we have crash dumps, for instance. Or other things that start to happen very frequently. The good news is that as of SQL Server 2012, we can set a max size for the errorlog file. There is no GUI for this, so we have to manipulate the registry directly. Again, we can use xp_instance_regwrite. Below will limit the size to 30 MB:
With 15 files, you can patch of your SQL Server machine without aging out all old errorlog files. And with a max size of 30 MB, you keep each file manageable in size. And you keep the total size of errorlog files for that instance to 450 MB. Not enough to fill your disks. But enough to have historical information for when you are about to perform a health check on your SQL Server instance.
References: this by Jan Kåre and this by Paul Randal.
You probably know that you can mirror a backup to several destinations, assuming you are on a supported edition (Enterprise or Developer). This is not the same as striping; you can compare striping to RAID 0, and mirroring to RAID 1.
Ola now supports mirroring in his maintenance solution, found here. A couple of examples:
Note that if any of the destinations are unanavilable, then the backup fails for all destinations. SQL Server do not produce the backup to the ones that are available. This has nothing to do with Ola’s solution, it is just how MS decided to implement backup mirroring.
Never? You are not alone. None of the maintenance solutions I use includes functionality to rebuild a heap, and that includes Maintanance Plans and Ola Hallengren’s maintenance solution.
“So why would you want to rebuild a heap, when it isn’t sorted in the first place?”, you ask. The answer is to get rid of Forwarding Pointers, and these can really hurt performance by adding lots more logical and physical reads, and random I/O. See for instance this from Kalen Delaney, this from Hugo Kornelis and this from the SQLCAT team.
SQL Server 2008 added the ALTER TABLE command, with the REBUILD clause. And this is what I’m using in my procedure rebuild_heaps which rebuilds all fragmented heaps on a SQL Server.
Database Mail has a couple of log tables in the msdb database. These can become large over time. I’ve seen MSDB databases over 1 GB in size, where normal size is less than 50 MB (heavy usage of old SSIS deployment model excluded).
Unfortunately Maintenance Plans do not have built-in functionality for this, nor does Ola Hallengren’s excellent maintenance solution ( http://ola.hallengren.com/ ). All you have to do is to schedule an agent job to be executed, say, every week, having one T-SQL jobstep containing:
DECLARE @DeleteOlder DATETIME
SET @DeleteOlder = DATEADD(MONTH, -1, CURRENT_TIMESTAMP)