Measuring things can be difficult. I have been painfully reminded of that with my attempts to measure whether fragmentation matters with new hardware. I created a test script in which I read data seeking the index (following the linked list of the leaf level of the index).
My thoughts were that “jumping back and forth” doesn’t matter with modern I/O subsystems. But perhaps read-ahead reads more (unnecessary) data into cache and less useful data remains in memory because of this?
In my first post, came to the conclusion that it didn’t matter for execution time, but I noticed that lots of memory was brought into cache when the index was fragmented. There’s some background info in there: http://sqlblog.karaszi.com/does-index-fragmentation-matter/ .
In my second blog post, I focused on how much memory was brought into cache. And I found that when the index was fragmented, I noticed 1000 times more memory usage. Surely, read-ahead, cannot cause this!? http://sqlblog.karaszi.com/index-fragmentation-part-2/
Because of the absurde figures, I had to dig deeper. Paul White told me about a lesser known optimization where SQL server will do “large I/O” (my own term for this) if you have plenty of unused memory. Instead of reading single pages, it reads whole extents. This makes sense, warming up the cache. https://blogs.msdn.microsoft.com/ialonso/2011/12/09/the-read-ahead-that-doesnt-count-as-read-ahead/
But still, that can’t account for 1000 times more memory usage for a fragmented index. I can live with 5-10 times, but not 1000 times. And then Simon Sabin pointed out the obvious: auto-update of statistics! My first set of SELECTs was done after a updating a bunch of rows (so to fragment the index), and that triggered auto update statistics (bringing the whole index into memory). Mystery solved.
My findings
As I said, I found it extremely difficult to measure this. Things happens in the machine which can muddle the results. I did the test over and over again. Looking at both details and averages. My conclusion is that with same amount of pages, you will see a pretty marginal effect of fragmentation. “Marginal” is in the eye of the beholder, though. More details further down. Please read my earlier posts, especially the first one for background information.
What about page fullness?
To be honest, I find this to be a much more interesting aspect. I’d like to split this into two sub-sections. Increasing and “random” index.
Increasing index
This can be like an identity or ever increasing datetime column (think for instance order_date). This will not become fragmented from INSERTS and assuming that you don’t delete “every other row”, then you will end up with a nice unfragmented index with a high degree of page fullness. If you rebuild it with a fillfactor of 100%, you have just wasted resources. If you rebuild it with a lower fillfactor, you also waste space and cause SQL Server to read more data – causing worse performance.
Random index
By this I mean index where the data distribution is all over the place. For instance an index on the LastName column. As you insert data, pages are split and you end up with a fillfactor of about 75% (which is in between a half-full and a full page). If you rebuild it with a similar fillfactor, you didn’t gain anything. If you rebuild it with a high fillfactor, then the following activity in your database will generate a high number of page splits. It seems reasonable to let it be, accepting a fillfactor of about 75% and accept a page split every now and then.
But we also delete data!
Do you? Really? OK, let us say that you do. What is the delete pattern? And the degree of deletes? How does this spread over your particular index? Deleting old data over some ever increasing index will just deallocate those pages. Deleting data which doesn’t match with the index key (rows deleted are spread all over the index) will leave empty space. This will be re-used as you insert new rows. But if you delete a lot of data, then you will have a low degree of page fullness. IMO, this is a rather unusual situation and should warrant a manually triggered index maintenance, in contrast to rebuilding indexes every week or so.
(And don’t get me started on heaps, but surely you don’t have those…? I once had a SELECT of all rows for a table with only 3000 rows, which took minutes. It had allocated more extents than number of rows in the table. Rebuild it, and it took, of course, sub-second. Needless to say, this didn’t stay as a heap for long. And no, the table wasn’t wide, at all.)
Bottom line?
Being who I am, I don’t want to draw too hard conclusions from some tests and reasoning. But I must say that I doubt the value of regular index defrag – assuming you are on some modern I/O subsystem, of course. I think that folks focus on index defrag and forget about statistics. I like to provide the optimizer with as high-quality statistics as possible. Sure, index rebuild will give you new statistics. But if you condition it based on fragmentation, then you end up with not rebuilding a bunch of indexes and have stale statistics. Auto update statistics is OK, but you have to modify a decent amount of data before it kicks in. And when it kicks in, the user waits for it. Unless you do async update…. But I digress. Statistics management is a topic of its own. My point is that you probably don’t want to lose track of statistics management because you keep staring as index fragmentation.
My tests – details
Check out this section if you are curious of how I did it, want to see the numbers and perhaps even do tests of your own. I welcome constructive criticism which can be weaknesses etc in my test scripts. Or perhaps different interpretations of the outcome!
The basic flow is:
- Create a proc which does bunch of reads to fill the buffer pool with data.
- Create some other supporting stuff, like trace definition, trace control procedure etc.
- Grow the data and log files for the Stackoverflow (10 GB) database.
- Create table to hold my measures.
- Create the narrow_index table which is a table with a clustered index which is narrow. A row is some 40 bytes (very rough calculation off the top of my head).
- Create the wide_index is a table with a clustered index which is wider – some 340 bytes.
- Set max server memory to 1 GB.
- Turn off auto-update statistics.
- Create the proc that will do the tests.
- Generate fragmentation in both indexes/tables.
- The narrow table has 20,000,000 rows and is about 970 MB in size.
- The wide table has 10,000,000 rows and is about 6.8 GB in size.
- Run the proc that does the test with 1 row selectivity.
- Run the proc that does the test with 10000 rows selectivity.
- Run the proc that does the test with 100000 rows selectivity.
- Each test runs 99 SELECTs, spread over the data (so not to read the same row).
- Average the result, into a table named resx.
- I did 4 such iterations, so I have the tables res1, res2, res3 and res4.
- Check the numbers from these tables and see if they correspond reasonably. They did.
- Average the results from these four table to get the end results.
The procedure which executes the SELECTS and captures the measures has this basic flow
- Stop the (XE) trace if it is running.
- Delete all old trace files.
- Do a first SELECT to get rid of auto-stats (yeah, I disabled it, but just in case).
- Empty the cache.
- Reads lots of other data into cache.
- Start the trace
- Do the SELECT, in a loop, reading as many rows as requested (param to the proc), as many times as requested (another param to the proc). Don’t read the same data over and over again. This is done both for the narrow and wide table/index.
- Capture memory usage for each table (buffer pool usage).
- Get the trace raw data into a temp table.
- Parse the trace data/above table using XQuery into the measures table.
- Ie., we now have one row for each SELECT with a bunch of measures.
The measures
- Microseconds as captured with the Extended Event trace.
- Microseconds as “wall clock time”. I.e., capture datetime before the loop in a variable and calculate microseconds after the loop into a variable, divided by number of executions. This value will then be the same for each execution in the loop. I want to have two different ways to calculate execution time, as a sanity check. In the end, they corresponded pretty well.
- How much data of the table was brought into cache.
- Physical reads. This is of lower interest, since read-ahead will muddle the result.
- Logical reads. This is more interesting and can among other things be used to check t at we read about the same number of pages for the fragmented and for the non-fragmented index. Which we should – they have the same fillfactor!
- CPU microseconds. I didn’t find this very interesting.
Outcome
I ignored the reading of 1 row, this shouldn’t differ, and the small difference I found I attribute to imperfections in the ability to capture exact numbers.
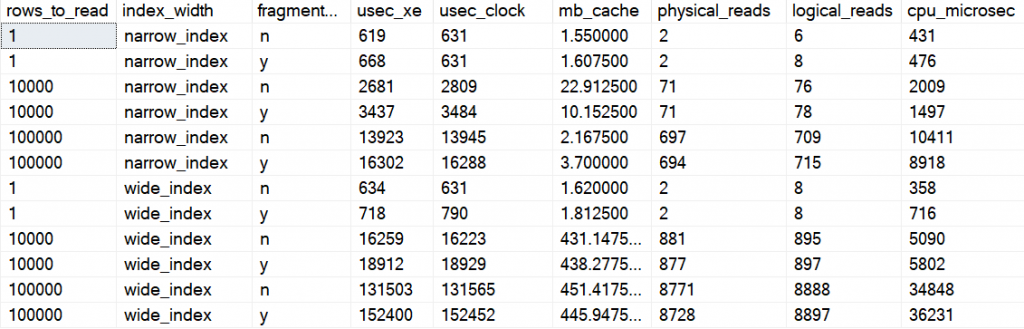
When reading 1000 rows for the narrow table, about 75 pages, the fragmented index was about 30% slower.
When reading some 700-900 pages (100,000 rows for the narrow table and 10,000 rows for the wide table) the fragmented table was about 16-17 % slower.
When reading about 9,000 pages (100,000 rows for the wide table), the fragmented index was about 15% slower.
Here are the averages, one row per execution (remember that I did 99 SELECTs in a loop, so this is the average of those):
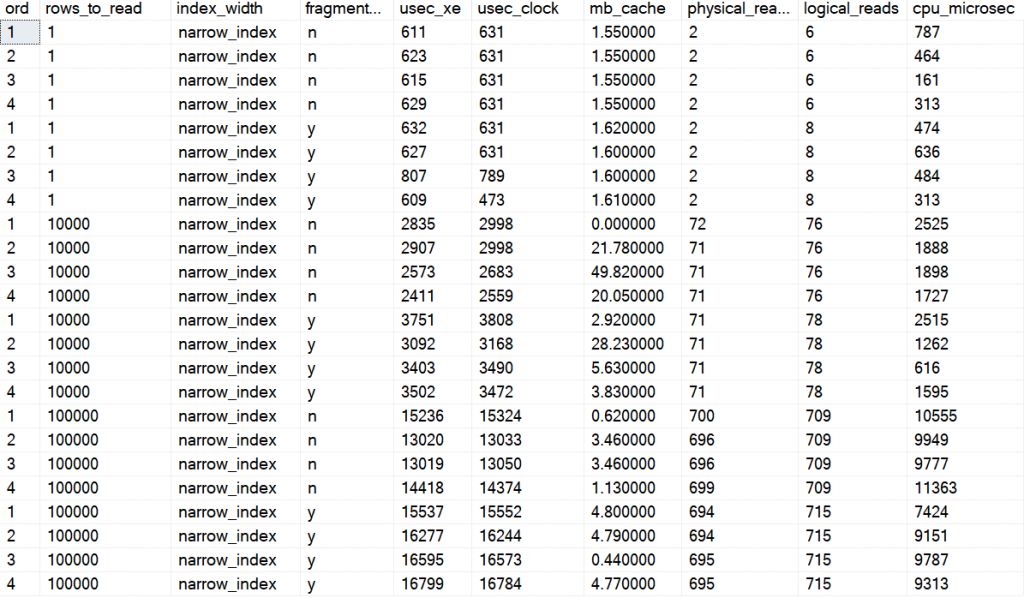
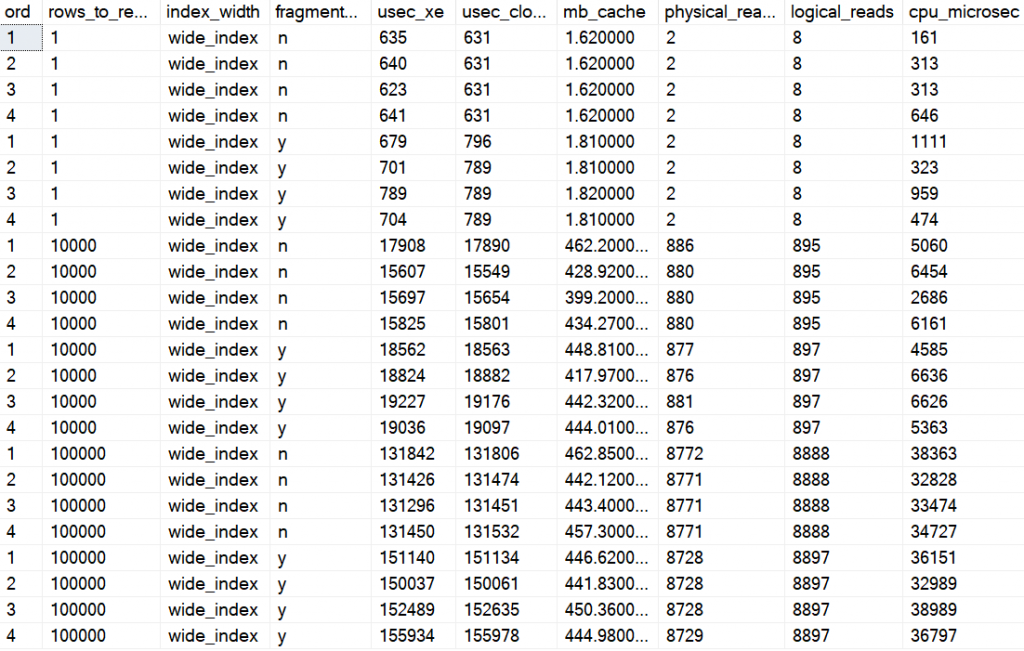
And here is the average of those averages
The code
------------------------------------------------------------------------------------------------
--Measure cost of fragmentation in terms of execution time and memory usage
--Tibor Karaszi, 2019
--Requires the Stackoverflow database. I was using the 10 GB version.
------------------------------------------------------------------------------------------------
SET NOCOUNT ON
------------------------------------------------------------------------------------------------
--Setup section
------------------------------------------------------------------------------------------------
USE StackOverflow
GO
--Proc to fill buffer pool, reads lots of data, takes a while to execute, especially if on spinning disk
CREATE OR ALTER PROC fill_bp
AS
DECLARE @a bigint
SET @a = (SELECT AVG(CAST(PostId AS bigint)) FROM Comments)
SET @a = (SELECT AVG(CAST(CommentCount AS bigint)) FROM Posts)
SET @a = (SELECT AVG(CAST(PostId AS bigint)) FROM Comments)
SET @a = (SELECT AVG(CAST(VoteTypeId AS bigint)) FROM Votes)
SET @a = (SELECT AVG(CAST(PostId AS bigint)) FROM Comments)
SET @a = (SELECT AVG(CAST(VoteTypeId AS bigint)) FROM Votes)
SET @a = (SELECT AVG(CAST(VoteTypeId AS bigint)) FROM Votes)
GO
--Disable IAM order scan, so we know that SQL Server will follow the linked list
--See https://sqlperformance.com/2015/01/t-sql-queries/allocation-order-scans
EXEC sp_configure 'cursor threshold', 1000000 RECONFIGURE
GO
--Proc to change trace status
CREATE OR ALTER PROC change_trace_status
@state varchar(50) --start, stop, delete_all_files
AS
IF @state = 'start'
BEGIN
IF NOT EXISTS (SELECT * FROM sys.dm_xe_sessions WHERE name = 'frag_test')
ALTER EVENT SESSION frag_test ON SERVER STATE = START
END
IF @state = 'stop'
BEGIN
IF EXISTS (SELECT * FROM sys.dm_xe_sessions WHERE name = 'frag_test')
ALTER EVENT SESSION frag_test ON SERVER STATE = STOP
END
--Delete XE file, using xp_cmdshell (ugly, I know)
IF @state = 'delete_all_files'
BEGIN
EXEC sp_configure 'xp_cmdshell', 1 RECONFIGURE WITH OVERRIDE
EXEC xp_cmdshell 'DEL R:\frag_test*.xel', no_output
EXEC sp_configure 'xp_cmdshell', 0 RECONFIGURE WITH OVERRIDE
END
/*
EXEC change_trace_status @state = 'start'
EXEC change_trace_status @state = 'stop'
EXEC change_trace_status @state = 'delete_all_files'
*/
GO
--Drop and create event session to keep track of execution time
EXEC change_trace_status @state = 'stop'
WAITFOR DELAY '00:00:01'
IF EXISTS (SELECT * FROM sys.server_event_sessions WHERE name = 'frag_test')
DROP EVENT SESSION frag_test ON SERVER
EXEC change_trace_status @state = 'delete_all_files'
CREATE EVENT SESSION frag_test ON SERVER
ADD EVENT sqlserver.sp_statement_completed()
ADD TARGET package0.event_file(SET filename=N'R:\frag_test')
WITH (MAX_DISPATCH_LATENCY=10 SECONDS)
GO
--Create proc to report progress
CREATE OR ALTER PROC #status
@msg varchar(200)
AS
RAISERROR(@msg, 10, 1) WITH NOWAIT
GO
--Grow the data and log files for StackOverflow database.
EXEC #status 'Grow the data and log files for StackOverflow database...'
IF EXISTS( SELECT size * 8/(1024*1024), *
FROM sys.database_files
WHERE name = N'StackOverflow2010' AND size * 8/(1024*1024) < 30)
ALTER DATABASE [StackOverflow] MODIFY FILE ( NAME = N'StackOverflow2010', SIZE = 30GB )
IF EXISTS( SELECT size * 8/(1024*1024), *
FROM sys.database_files
WHERE name = N'StackOverflow2010_log' AND size * 8/(1024*1024) < 15)
ALTER DATABASE [StackOverflow] MODIFY FILE ( NAME = N'StackOverflow2010_log', SIZE = 15GB )
GO
--Table to hold output
DROP TABLE IF EXISTS measures
CREATE TABLE measures (
id int identity(1,1) PRIMARY KEY NOT NULL
,rows_to_read int NOT NULL
,index_width varchar(20) NOT NULL
,fragmented varchar(2) NOT NULL
,usec_xe bigint NOT NULL
,usec_clock bigint NOT NULL
,cpu_microsec bigint NOT NULL
,physical_reads bigint NOT NULL
,logical_reads bigint NOT NULL
,mb_cache decimal(9,2) NOT NULL
);
--Create the table for the narrow index
EXEC #status 'Setup section. Create table with narrow index...'
DROP TABLE IF EXISTS narrow_index
--Adjust numbers. 20,000,000 rows means about 970 MB in the end
SELECT TOP(1000*1000*20) ROW_NUMBER() OVER( ORDER BY (SELECT NULL)) AS c1, CAST('Hello' AS varchar(80)) AS c2
INTO narrow_index
FROM sys.columns AS a, sys.columns AS b, sys.columns AS c
CREATE CLUSTERED INDEX x ON narrow_index(c1)
--Create the table for the wide index
EXEC #status 'Setup section. Create table with wide index...'
DROP TABLE IF EXISTS wide_index
--Adjust numbers. 10,000,000 rows means about 6.8 GB in the end
SELECT
TOP(1000*1000*10) ROW_NUMBER() OVER( ORDER BY (SELECT NULL)) AS c1
,CAST('Hi' AS char(80)) AS c2
,CAST('there' AS char(80)) AS c3
,CAST('I''m' AS char(80)) AS c4
,CAST('on' AS char(80)) AS c5
,CAST('my' AS varchar(200)) AS c6
INTO wide_index
FROM sys.columns AS a, sys.columns AS b, sys.columns AS c
CREATE CLUSTERED INDEX x ON wide_index(c1)
GO
------------------------------------------------------------------------------------------------
--Investigate the data if you want
/*
--wide index
SELECT TOP(100) * FROM wide_index
EXEC sp_indexinfo wide_index --Found on my web-site
EXEC sp_help 'wide_index'
--narrow index
SELECT TOP(100) * FROM narrow_index
EXEC sp_indexinfo narrow_index --Found on my web-site
EXEC sp_help 'narrow_index'
*/
--Execute this if you want to have a rather full BP, restricts memory to 1 GB
EXEC sp_configure 'max server memory', 1000 RECONFIGURE
--Turn off auto-update statistics
ALTER DATABASE Stackoverflow SET AUTO_UPDATE_STATISTICS OFF
------------------------------------------------------------------------------------------------
--/Setup section
------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------
--Create the proc that executes our SQL
EXEC #status 'Create the proc that executes our SQL...'
GO
CREATE OR ALTER PROC run_the_sql
@fragmented varchar(20)
,@rows_to_read int
,@range_iterations int
,@fill_bp char(1) --'y' or 'n'
,@report_frag char(1) = 'n'
AS
DECLARE
@sql varchar(1000)
,@sql_condition varchar(1000)
,@bp_wide_mb decimal(9,2)
,@bp_narrow_mb decimal(9,2)
,@range_start int
,@range_iterations_counter int
,@a int
,@start_time datetime2
,@exec_time_wide_index_usec bigint
,@exec_time_narrow_index_usec bigint
EXEC change_trace_status @state = 'stop'
EXEC change_trace_status @state = 'delete_all_files'
--Do a first execution to get autostats etc out of the way
DBCC FREEPROCCACHE
SET @range_iterations_counter = 1
SET @range_start = 1000
SET @a = (SELECT COUNT_BIG(c1) AS c1_count FROM wide_index WHERE c1 BETWEEN @range_start AND (@range_start + @rows_to_read - 1))
SET @a = (SELECT COUNT_BIG(c1) AS c1_count FROM narrow_index WHERE c1 BETWEEN @range_start AND (@range_start + @rows_to_read - 1))
--Empty data cache (buffer pool, BP)
CHECKPOINT
DBCC DROPCLEANBUFFERS
--Run proc to read stuff into BP if requested
IF @fill_bp = 'y'
EXEC fill_bp
EXEC change_trace_status @state = 'start'
--Do the SELECTs, narrow index
SET @range_iterations_counter = 1
SET @range_start = 1000
SET @start_time = SYSDATETIME()
WHILE @range_iterations_counter <= @range_iterations
BEGIN
SET @a = (SELECT COUNT_BIG(c1) AS c1_count FROM narrow_index WHERE c1 BETWEEN @range_start AND (@range_start + @rows_to_read - 1))
SET @range_start = @range_start + 100000
SET @range_iterations_counter += 1
END
SET @exec_time_narrow_index_usec = DATEDIFF_BIG(microsecond, @start_time, SYSDATETIME()) / @range_iterations
--Do the SELECTs, wide index
SET @range_iterations_counter = 1
SET @range_start = 1000
SET @start_time = SYSDATETIME()
WHILE @range_iterations_counter <= @range_iterations
BEGIN
SET @a = (SELECT COUNT_BIG(c1) AS c1_count FROM wide_index WHERE c1 BETWEEN @range_start AND (@range_start + @rows_to_read - 1))
SET @range_start = @range_start + 100000
SET @range_iterations_counter += 1
END
SET @exec_time_wide_index_usec = DATEDIFF_BIG(microsecond, @start_time, SYSDATETIME()) / @range_iterations
EXEC change_trace_status @state = 'stop'
--Keep track of BP usage
SET @bp_wide_mb =
(
SELECT
CAST((COUNT(*) * 8.00) / 1024 AS DECIMAL(9,2)) AS MB
FROM sys.allocation_units AS a
JOIN sys.dm_os_buffer_descriptors AS b
ON a.allocation_unit_id = b.allocation_unit_id
JOIN sys.partitions AS p
ON a.container_id = p.hobt_id
WHERE p.object_id = OBJECT_ID('wide_index')
AND b.database_id = DB_ID()
)
SET @bp_narrow_mb =
(
SELECT
CAST((COUNT(*) * 8.00) / 1024 AS DECIMAL(9,2)) AS MB
FROM sys.allocation_units AS a
JOIN sys.dm_os_buffer_descriptors AS b
ON a.allocation_unit_id = b.allocation_unit_id
JOIN sys.partitions AS p
ON a.container_id = p.hobt_id
WHERE p.object_id = OBJECT_ID('narrow_index')
AND b.database_id = DB_ID()
)
--Wait for trace data to arrive in target
WAITFOR DELAY '00:00:10'
--Get the trace data into our table
SELECT CAST(event_data AS XML) AS StatementData
INTO #myRawXeData
FROM sys.fn_xe_file_target_read_file('R:\frag_test*.xel', NULL, NULL, NULL);
--Done with trace file, delete it
EXEC change_trace_status @state = 'delete_all_files';
--Transform raw trace data into our measures table
WITH t AS(
SELECT
StatementData.value('(event/data[@name="duration"]/value)[1]','bigint') AS duration_microsec
,StatementData.value('(event/data[@name="cpu_time"]/value)[1]','bigint') AS cpu_microsec
,StatementData.value('(event/data[@name="physical_reads"]/value)[1]','bigint') AS physical_reads
,StatementData.value('(event/data[@name="logical_reads"]/value)[1]','bigint') AS logical_reads
,StatementData.value('(event/data[@name="statement"]/value)[1]','nvarchar(500)') AS statement_
FROM #myRawXeData AS evts
WHERE StatementData.value('(event/data[@name="statement"]/value)[1]','nvarchar(500)') LIKE '%index WHERE c1%'
),
t2 AS (
SELECT
CASE WHEN t.statement_ LIKE '%wide_index%' THEN 'wide_index' ELSE 'narrow_index' END AS index_width
,CASE @fragmented WHEN 'high_frag_level' THEN 'y' ELSE 'n' END AS fragmented
,duration_microsec
,CASE WHEN t.statement_ LIKE '%wide_index%' THEN @exec_time_wide_index_usec ELSE @exec_time_narrow_index_usec END AS usec_clock
,cpu_microsec
,physical_reads
,logical_reads
,CASE WHEN t.statement_ LIKE '%wide_index%' THEN @bp_wide_mb ELSE @bp_narrow_mb END AS mb_cache
FROM t)
INSERT INTO measures(rows_to_read, index_width, fragmented, usec_xe, usec_clock, cpu_microsec, physical_reads, logical_reads, mb_cache)
SELECT @rows_to_read, index_width, fragmented, duration_microsec, usec_clock, cpu_microsec, physical_reads, logical_reads, mb_cache
FROM t2;
--Report fragmentation level, if requested
IF @report_frag = 'y'
--Note size of index and frag level, should be comparative between executions
SELECT
OBJECT_NAME(object_id) AS table_name
,index_type_desc
,CAST(avg_fragmentation_in_percent AS decimal(5,1)) AS frag_level
,page_count/1000 AS page_count_1000s
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'LIMITED')
WHERE index_level = 0 AND alloc_unit_type_desc = 'IN_ROW_DATA' AND OBJECT_NAME(object_id) IN('narrow_index', 'wide_index')
ORDER BY index_id
GO
------------------------------------------------------------------------------------------------
--1: Generate fragmentation in both indexes
--Fragment wide ix
EXEC #status 'Generate fragmentation in wide index...'
UPDATE wide_index SET c6 = REPLICATE('a', 200) WHERE c1 % 20 = 0
UPDATE STATISTICS wide_index WITH FULLSCAN
--Fragment narrow ix
EXEC #status 'Generate fragmentation in narrow index...'
UPDATE narrow_index SET c2 = REPLICATE('a', 20) WHERE c1 % 100 = 0
UPDATE STATISTICS narrow_index WITH FULLSCAN
--Run the queries
EXEC #status 'Run queries with high frag level...'
EXEC run_the_sql @fragmented = 'high_frag_level', @rows_to_read = 1, @range_iterations = 99, @fill_bp = 'y'
EXEC run_the_sql @fragmented = 'high_frag_level', @rows_to_read = 10000, @range_iterations = 99, @fill_bp = 'y'
EXEC run_the_sql @fragmented = 'high_frag_level', @rows_to_read = 100000, @range_iterations = 99, @fill_bp = 'y'
-----------------------------------------------------------------------------------
--2: no frag in either index, fillfactor set to make same size as when fragmented
EXEC #status 'Eliminate fragmentation in wide index...'
ALTER INDEX x ON wide_index REBUILD WITH (FILLFACTOR = 48)
EXEC #status 'Eliminate fragmentation in narrow index...'
ALTER INDEX x ON narrow_index REBUILD WITH (FILLFACTOR = 50)
--Run the queries
EXEC #status 'Run queries with low frag level...'
EXEC run_the_sql @fragmented = 'low_frag_level', @rows_to_read = 1, @range_iterations = 99, @fill_bp = 'y'
EXEC run_the_sql @fragmented = 'low_frag_level', @rows_to_read = 10000, @range_iterations = 99, @fill_bp = 'y'
EXEC run_the_sql @fragmented = 'low_frag_level', @rows_to_read = 100000, @range_iterations = 99, @fill_bp = 'y'
-----------------------------------------------------------------------------------
-----------------------------------------------------------------------------------
--Reset
EXEC sp_configure 'cursor threshold', -1
EXEC sp_configure 'max server memory', 2147483647
RECONFIGURE
GO
-----------------------------------------------------------------------------------
-----------------------------------------------------------------------------------
--Run below manually and investigate the output
--Raw data from the trace
SELECT * FROM measures ORDER BY rows_to_read, index_width, fragmented
--Average the data.
--Note that I ran this script 4 times and used INTO here to create 4 tables. Res1, res2, res3, and res4.
SELECT
m.rows_to_read
,m.index_width
,m.fragmented
,AVG(m.usec_xe) AS usec_xe
,AVG(m.usec_clock) AS usec_clock
,AVG(m.mb_cache) AS mb_cache
,AVG(m.physical_reads) AS physical_reads
,AVG(m.logical_reads) AS logical_reads
,AVG(m.cpu_microsec) AS cpu_microsec
-- INTO res4 --if you want to persist the results
FROM measures AS m
GROUP BY m.rows_to_read, m.index_width, m.fragmented
ORDER BY index_width, rows_to_read, fragmented;
--Check the details from the averages of each execution
WITH x AS(
SELECT 1 AS ord, * FROM res1
UNION ALL
SELECT 2 AS ord, * FROM res2
UNION ALL
SELECT 3 AS ord, * FROM res3
UNION ALL
SELECT 4 AS ord, * FROM res4
)
SELECT * FROM x
WHERE index_width = 'narrow_index'
ORDER BY index_width, rows_to_read, fragmented, ord;
--Average the averages
WITH x AS(
SELECT 1 AS ord, * FROM res1
UNION ALL
SELECT 2 AS ord, * FROM res2
UNION ALL
SELECT 3 AS ord, * FROM res3
UNION ALL
SELECT 4 AS ord, * FROM res4
)
SELECT
m.rows_to_read
,m.index_width
,m.fragmented
,AVG(m.usec_xe) AS usec_xe
,AVG(m.usec_clock) AS usec_clock
,AVG(m.mb_cache) AS mb_cache
,AVG(m.physical_reads) AS physical_reads
,AVG(m.logical_reads) AS logical_reads
,AVG(m.cpu_microsec) AS cpu_microsec
FROM x AS m
GROUP BY m.rows_to_read, m.index_width, m.fragmented
ORDER BY index_width, rows_to_read, fragmented;
-----------------------------------------------------------------------------------
-----------------------------------------------------------------------------------
--Cleanup
/*
DROP TABLE IF EXISTS narrow_index
DROP TABLE IF EXISTS myXeData
DROP TABLE IF EXISTS myXeData2
DROP TABLE IF EXISTS bp_usage
*/
7 Replies to “Fragmentation, the final installment”
Comments are closed.